





머신러닝 적용사례 제 3장. Prophet 및 Apache Spark를 통한 세밀한 시계열 예측
시계열 예측의 발전으로 소매업체는 보다 안정적인 수요 예측을 할 수 있습니다.
이제 과제는 기업이 제품 재고를 정밀하게 조정할 수 있도록 세분화된 수준에서 시기적절하게 예측하는 것입니다.
이러한 문제에 직면한 점점 더 많은 기업들이
Apache Spark 및
Facebook Prophet을
활용하여 과거 솔루션의 확장성과 정확성 한계를 극복하게 되었습니다.
이 게시물에서는 시계열 예측의 중요성에 대해 논의하고 일부 샘플 시계열 데이터를 시각화한 다음
Facebook Prophet의
사용을 보여주는 간단한 모델을 구축할 것입니다.
단일 모델을 구축하는 데 익숙해지면
Prophet과
Apache Spark의 마법을 결합하여 한 번에 수백 개의 모델을 학습하는 방법을 보여줌으로써 개별 제품–스토어 조합에 대한 정확한 예측을 다음 수준에서 생성할 수 있습니다.
정확하고 시기적절한 예측이 그 어느 때보다 중요합니다
제품 및 서비스에 대한 수요를 더 잘 예측하기 위해 시계열 분석의 속도와 정확성을 개선하는 것은 소매업체의 성공에 매우 중요합니다.
너무 많은 제품이 매장에 배치되면 선반과 창고 공간이 부족하거나 유통기한이 만료될 수 있습니다.
또한 소매업체는 자금이 재고에 묶이게 됨으로써 제조업체나 소비자 패턴의 변화가 만들어내는 새로운 기회를 활용할 수 없게 되기도 합니다.
반면,
매장에 너무 적은 양의 제품이 배치되면 고객이 필요한 제품을 구매하지 못할 수 있습니다.
이러한 예측 오류는 소매업체의 즉각적인 수익 손실을 초래할 뿐만 아니라 시간이 지남에 따라 소비자 불만으로 인해 고객이 경쟁업체로 이동할 수 있습니다.
새로운 예측 기능은 보다 정확한 시계열 예측 방법과 모델을 필요로 합니다
얼마 동안 ERP(전사적 자원 관리)
시스템과 써드파티 솔루션은 소매업체에 단순한 시계열 모델을 기반으로 하는 수요 예측 기능을 제공했습니다.
그러나 기술의 발전과 해당 분야에 대한 요구가 늘어남에 따라 많은 소매업체는 선형 모델을 넘어 과거에 사용했던 기존 알고리즘을 넘어설 방법을 모색하고 있습니다.
Facebook
Prophet에서 제공하는 것과 같은 새로운 기능이 데이터 과학 커뮤니티에서 등장하고 있으며 기업은 이러한 머신 러닝 모델을 시계열 예측 요구 사항에 적용할 수
있는 유연성을 모색하고 있습니다.
전통적인 예측 솔루션에서 벗어나는 이러한 움직임은 소매업체 등이 수요 예측의 복잡성 뿐만 아니라 수십만 또는 수백만 개의 머신 러닝 모델을 적시에 생성하는 데 필요한 작업의 효율적인 분배를 위해 사내 전문가를 양성할 것을 요구합니다.
다행히
Spark를 사용하여 이러한 모델의 교육을 배포할 수 있으므로 제품 및 서비스에 대한 전체 수요 뿐만 아니라 각각의 점포별로 제품에 대한 고유한 수요를 예측할 수 있습니다.
시계열 데이터에서 수요의 계절적 변동 시각화하기
Prophet을 사용하여 개별 상점 및 제품에 대한 세밀한 수요 예측을 생성하는 방법을 보여주기 위해
Kaggle에서 공개적으로 사용 가능한 데이터 세트를 사용할 것입니다.
10개 매장의
50개 개별 품목에 대한
5년간의 일일 판매 데이터로 구성됩니다.
먼저, 모든 제품과 매장에 대한 전반적인 연간 판매 동향을 살펴보겠습니다.
보시다시피,
전체 제품 판매는 매년 증가하고 있습니다.
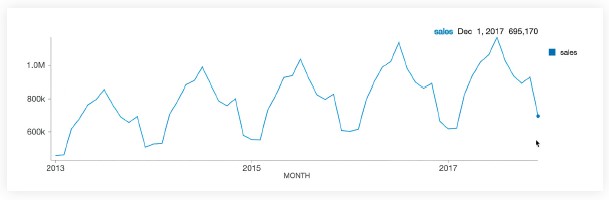
다음으로, 같은 데이터를 월 단위로 보면 전년 대비 상승 추세가 매월 꾸준히 진행되지 않는 것을 알 수 있습니다.
대신,
우리는 여름에 최고점과 겨울에 최저점의 명확한 계절 패턴을 봅니다.
Databricks
Collaborative Notebooks의 기본 제공 데이터 시각화 기능을 사용하여 차트 위에 마우스를 올려 놓으면 매월 데이터 값을 볼 수 있습니다.
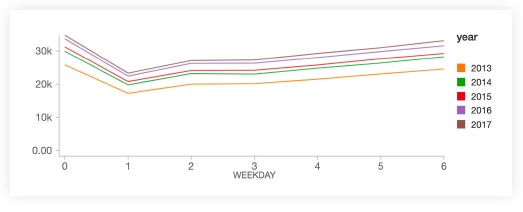
일별로 보면, 판매는 일요일(weekday
0)에 최고조에 달하고 월요일(weekday
1)에 급격히 감소한 다음 나머지 기간 동안 꾸준히 회복됩니다.
Facebook Prophet에서 간단한 시계열 예측 모델 시작하기
위의 차트에서 볼 수 있듯이 매출은 연간
/ 주간 단위의 계절적 패턴을 보여주며 전년 대비 상승하는 모습을 보여줍니다.
Prophet은 이러한 중복 패턴을 분석하도록 설계되어 있습니다.
Facebook Prophet은
scikit-learn API를
따르므로
sklearn에 대한 경험이 있는 사람이라면 누구나 쉽게 사용할 수 있습니다.
2열
pandas DataFrame을
입력으로 전달해야 합니다.
첫번째 열은 날짜이고 두번째 열은 예측할 값(이 경우에는 판매)입니다.
데이터가 적절한 형식이 되면 모델을 쉽게 구축할 수 있습니다.

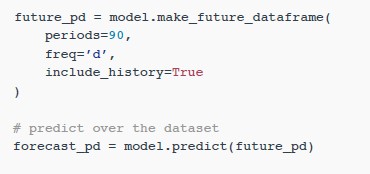
이제 모델을 데이터에 맞추었으므로 이를 사용하여
90일 예측을 작성해 보겠습니다.
아래 코드에서는
Prophet의 make_future_dataframe 메서드를 사용하여 과거 날짜와
90일 이후를 모두 포함하는 데이터 세트를 정의합니다.
자, 이제
Prophet의 내장
.plot 메서드를 사용하여 실제 데이터와 예측 데이터가 정렬되는 방식과 미래 예측을 시각화할 수 있습니다.
보시다시피 앞서 설명한 주간 및 계절별 수요 패턴이 실제로 예측 결과에 반영됩니다.

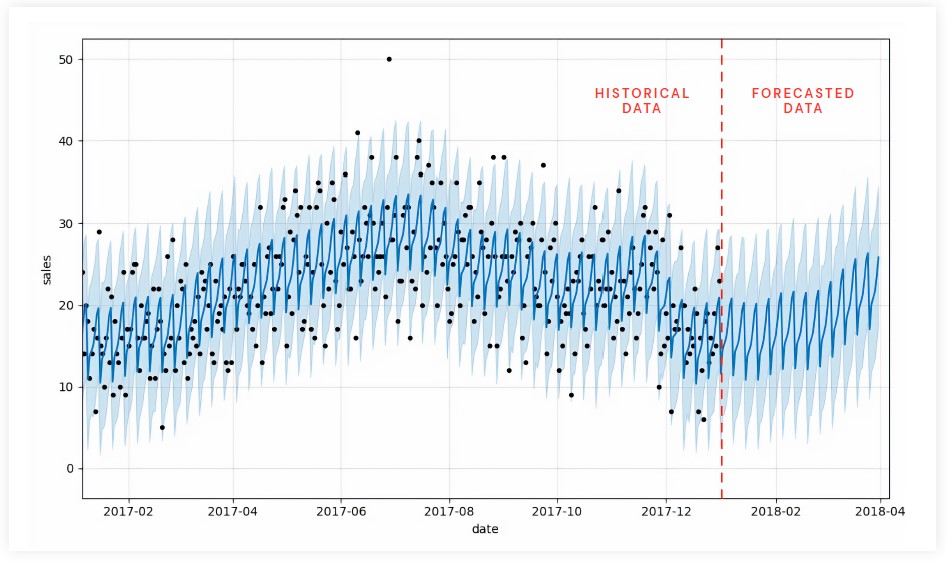
이 시각화는 약간 혼잡합니다.
Bartosz Mikulski는
확인할만한 가치가 있는 훌륭한 분석을 제공합니다.
간단히 말해서,
검은 점은 우리의 예측을 나타내는 더 어두운 파란색 선과 우리의
(95%) 불확실성 구간을 나타내는 더 밝은 파란색 띠로 실제를 나타냅니다.
Prophet 및 Spark와 병렬로 수백 개의 시계열 예측 모델 학습
단일 시계열 예측 모델을 구축하는 방법을 시연했으므로 이제
Apache Spark의 기능을 사용하여 노력을 배가할 수 있습니다.
우리의 목표는 전체 데이터 세트에 대해 하나의 예측값을 생성하는 것이 아니라 각 제품–스토어 조합에 대해 수백 개의 모델과 예측값을 생성하는 것입니다.
이러한 방식으로 모델을 구축하면 예를 들어 한 식료품점 체인이 지점마다 다른 수요에 기반하여 Cleveland 매장에서 필요한 양과 달리 Sandusky 매장에서 주문해야 하는 우유의 양을 정확하게 예측할 수 있습니다.
시계열 데이터 처리를 분산하기 위해 Spark DataFrames를 사용하는 방법
데이터 과학자는 Apache Spark와 같은 분산 데이터 처리 엔진을 사용하여 많은 수의 모델을 교육하는 문제를 자주 해결합니다.
Spark 클러스터를 활용하여 클러스터의 개별 작업자 노드는 다른 작업자 노드와 병렬로 모델의 하위 집합을 학습할 수 있으므로 전체 시계열 모델 컬렉션을 학습하는 데 필요한 전체 시간을 크게 줄일 수 있습니다.
물론 작업자 노드(컴퓨터)
클러스터에서 모델을 학습하려면 더 많은 클라우드 인프라가 필요하며 여기에는 대가가 따릅니다.
그러나 온디맨드 클라우드 리소스를 쉽게 사용할 수 있기 때문에 기업은 필요한 리소스를 신속하게 프로비저닝하고,
모델을 교육하고,
해당 리소스를 신속하게 릴리스할 수 있으므로 물리적 자산에 대한 장기적인 약정 없이 대규모 확장성을 달성할 수 있습니다.
Spark에서 분산 데이터 처리를 달성하기 위한 핵심 메커니즘은
DataFrame입니다.
데이터를
Spark DataFrame에
로드하면 데이터가 클러스터의 작업자 전체에 분산됩니다.
이를 통해 이러한 작업자는 데이터의 하위 집합을 병렬 방식으로 처리하여 작업을 수행하는 데 필요한 전체 시간을 줄일 수 있습니다.
물론 각 작업자는 작업을 수행하는 데 필요한 데이터 하위 집합에 액세스할 수 있어야 합니다.
키 값에 대한 데이터를 그룹화하여(이 경우 상점 및 항목 조합에 대해)
해당 키 값에 대한 모든 시계열 데이터를 특정 작업자 노드로 가져옵니다.
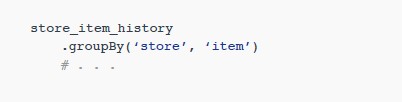
다음 섹션에서 UDF를 설정하고 데이터에 적용할 때까지는 실제로 작동하지 않겠지만 여러 모델을 병렬로 효율적으로 학습할 수 있으므로
GroupBy 코드를 여기에 공유합니다.
pandas 사용자 정의 함수의 힘 활용
시계열 데이터를 상점 및 품목별로 적절하게 그룹화 했으므로 이제 각 그룹에 대해 단일 모델을 학습해야 합니다.
이를 수행하기 위해 우리는
DataFrame의 각 데이터 그룹에 사용자 정의 함수를 적용할 수 있는
pandas UDF(사용자 정의 함수)를 사용할 수 있습니다.
이 UDF는 각 그룹에 대한 모델을 학습할 뿐만 아니라 해당 모델의 예측을 나타내는 결과 집합을 생성합니다.
그러나 함수가 다른 그룹과 독립적으로
DataFrame의 각 그룹에 대해 학습하고 예측하는 동안 각 그룹에서 반환된 결과는 단일 결과
DataFrame으로 편리하게 수집됩니다.
이를 통해 매장 항목 수준 예측을 생성할 수 있지만 결과를 단일 출력 데이터 세트로 분석가와 관리자에게 제공할 수 있습니다.
다음의 축약된 Python 코드에서 볼 수 있듯이
UDF를 빌드하는 것은 비교적 간단합니다.
UDF는 반환할 데이터의 스키마와 수신할 데이터 유형을 식별하는
pandas_udf 메서드로 인스턴스화됩니다.
바로 다음에
UDF의 작업을 수행할 함수를 정의합니다.
함수 정의 내에서 모델을 인스턴스화하고 설정하며,
받은 데이터에 맞춥니다.
모델은 예측을 수행하고 해당 데이터는 함수의 출력으로 반환됩니다.

이제 모든 것을 함께 가져오기 위해 앞에서 설명한
groupBy 명령을 사용하여 데이터 세트가 특정 상점 및 항목 조합을 나타내는 그룹으로 적절하게 분할되었는지 확인합니다.
그런 다음
UDF를
DataFrame에 적용하기만 하면
UDF가 모델에 적합하고 각 데이터 그룹화에 대해 예측할 수 있습니다.
각 그룹에 함수를 적용하여 반환된 데이터 세트는 예측을 생성한 날짜를 반영하도록 업데이트됩니다.
이것은 우리가 결국 우리의 기능을 프로덕션으로 가져갈 때 다른 모델 실행 중에 생성된 데이터를 추적하는 데 도움이 될 것입니다.

다음 단계
이제 각 상점–항목 조합에 대한 시계열 예측 모델을 구성했습니다.
분석가는
SQL 쿼리를 사용하여 각 제품에 대한 맞춤형 예측을 볼 수 있습니다.
아래 차트에서 우리는
10개 매장에서 제품
#1에 대한 예상 수요를 표시했습니다.
보시다시피 수요 예측은 매장마다 다르지만 일반적인 패턴은 예상대로 모든 매장에서 일관됩니다.
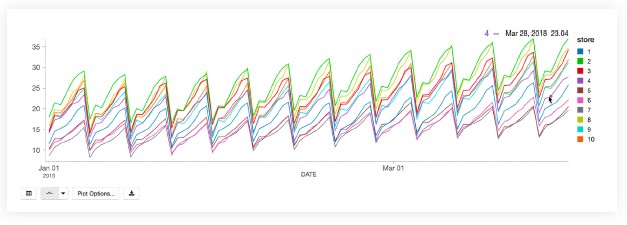
새로운 판매 데이터가 도착하면 새로운 예측을 효율적으로 생성하고 이를 기존 테이블 구조에 추가할 수 있으므로 분석가는 상황이 변화함에 따라 비즈니스의 기대치를 업데이트할 수 있습니다.
자세히 알아보려면 Facebook Prophet 및
Azure Databricks를
사용하여
Starbucks가 규모에 맞게 수요를 예측하는 방법이라는 제목의 주문형 웨비나를 시청하십시오.
순환 신경망으로 다변수 시계열 예측 수행하기
시계열 예측을 위해 Keras의
LSTM(장단기 메모리)
구현 사용
시계열 예측은 머신 러닝에서 중요한 영역입니다.
시계열 데이터의 특성으로 인해 정확한 모델을 구축하기 어려울 수 있습니다.
머신 러닝의 신경망 측면에서 최근 발전으로 우리는 범위를 벗어나거나 고전적인 시계열 예측 접근 방식으로 수행하기 어려운 다양한 문제를 해결할 수 있습니다.
이 게시물에서는 시계열 예측을 위해
Keras의
LSTM(Long Short-Term Memory) 구현을 사용하고 모델 실행 추적을 위한 MLfLow를 사용하는 방법을 보여줍니다.
LSTM이란 무엇입니까?
LSTM은
RNN(Recurrent Neural Network) 유형으로 네트워크가 이전의 여러 시간 단계에서 주어진 시간에 장기 종속성을 유지할 수
있도록 합니다.
RNN은 데이터의 출력 시퀀스가 입력 중 하나로 사용되는 뉴런에 대한 간단한 피드백 접근 방식을 사용하여 이러한 효과를 갖도록 설계되었습니다.
그러나 장기적인 종속성은 소멸 기울기 문제로 인해 네트워크를 학습할 수 없게 만들 수 있습니다.
LSTM은 바로 그 문제를 해결하도록 설계되었습니다.
때때로 정확한 시계열 예측은 이전 데이터와 최근 데이터의 조합에 따라 달라집니다.
LSTM은 간단한
DNN 아키텍처와 영리한 메커니즘을 결합하여 오랜 기간 동안 역사의 어떤 부분을
“기억“하고
“잊어야”
하는지 학습합니다.
긴 시퀀스에 걸쳐 데이터의 패턴을 학습하는
LSTM의 기능은 시계열 예측에 적합합니다.
LSTM 아키텍처의 이론적 토대는 여기(4장)를 참조하십시오.
올바른 문제와 올바른 데이터 세트 선택
미래 펀드 가격을 기반으로 포트폴리오를 생성하는 것부터 전력 공급망에 대한 수요 예측 등에 이르기까지 시계열의 수많은 적용사례가 있습니다.
LSTM의 가치를 보여주기 위해서는 먼저 올바른 문제가 필요하지만,
더 중요한 것은 올바른 데이터 세트가 필요합니다.
스마트 센서가 사전에 A/C를 켤 수 있도록 집의 습도와 온도를 미리 예측하는 방법을 배우고자 하거나 전기세를 절약하기 위해 미래에 소비할 전기량을 알고 싶다고 가정해 보겠습니다.
과거의 센서 및 온도 데이터는 관계를 학습하기에 충분해야 하며
LSTM이 도움이 될 수 있습니다.
이는 최근 센서 값뿐만 아니라 더 중요하게는 이전 값,
아마도 전날 같은 시간의 센서 값에 의존하기 때문입니다.
이를 위해 저전력 빌딩에서 가전 제품의 에너지 사용에 대한 실험 데이터를 사용합니다.
실험
이 실험을 위해 선택한 데이터 세트는 가전제품의 에너지 사용 회귀 모델을 구축하는 데 적합합니다.
집의 온도와 습도 조건은
ZigBee 무선 센서 네트워크로 모니터링되었습니다.
약
4.5개월 동안
10분 간격으로 진행됩니다.
에너지 데이터는
m-bus 에너지 미터로 기록되었습니다.
가장 가까운 공항 기상 관측소(벨기에
Chievres 공항)의 날씨는
Reliable Prognosis(rp5.ru)의
공개 데이터 세트에서 다운로드되었으며 날짜 및 시간 열을 사용하여 실험 데이터 세트와 병합되었습니다.
데이터 세트는
UCI Machine Learning 리포지토리에서 다운로드할 수
있습니다.
우리는 이것을 사용하여 다음 날 가전제품이 소비하는 에너지를 예측하는 모델을 학습할 것입니다.
데이터 모델링
신경망을 학습시키기 전에 네트워크가 일련의 과거 값에서 학습할 수 있는 방식으로 데이터를 모델링해야 합니다.
특히,
LSTM은 입력 특성의 수만큼 시간 단계별로 테스트 샘플 크기의 특정
3D 텐서 형식의 입력 데이터를 예상합니다.
지도 학습 접근 방식으로서
LSTM은 학습을 위해 기능과 레이블이 모두 필요합니다.
시계열 예측의 맥락에서 과거 값을 기능으로 제공하고 미래 값을 레이블로 제공하여
LSTM이 미래를 예측하는 방법을 배울 수 있도록 하는 것이 중요합니다.
따라서 시계열 데이터를
‘X’라는 기능의
2D 배열로 분해합니다.
여기서 입력 데이터는 배치의 원하는 시간 단계 수에서 겹치는 지연 값으로 구성됩니다.
입력 기능의 모든 배치에 대해 예측하려는 레이블 또는 미래 값으로만
구성된
‘y’라는
1D 배열을 생성합니다.
네트워크가 레이블의 과거 값에서도 학습할 수 있도록 입력 데이터에는
‘y’의 지연 값도 포함되어야 합니다.
자세한 설명은 다음 이미지를 참조하세요.
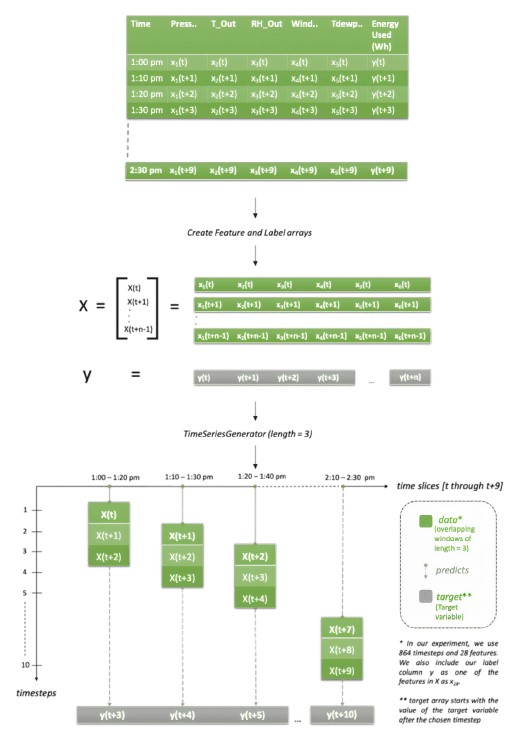
우리의 데이터 세트에는 10분 샘플이 있습니다.
위의 이미지에서
length= 3을 선택했습니다.
이는 모든 시퀀스(10분 간격)에
30분의 데이터가 있음을 의미합니다.
그 논리에 따르면 기능
‘X’는 값
[X(t), X(t+1), X(t+2)], [X(t+2), X(t+3), X(t+4)], [X(t+3), X(t+4), X(t+5)]… 등등.
그리고 목표 변수
‘y’는
[y(t+3), y(t+4), y(t+5)…y(t+10)]이어야 합니다. 시간 단계 또는 길이가
3과 같기 때문입니다.
그래서 우리는
y(t), y(t+1), y(t+2) 값을 무시할 것입니다. 또한 그래프에서 모든 입력 행에 대해 미래에 하나의 값만 예측한다는 것이 분명합니다.
즉,
y(t+n+1)입니다.
그러나 보다 현실적인 시나리오의 경우 아래 예에서 볼 수 있듯이
y(t+n+L)과 같이 미래에 더 멀리 예측하도록 선택할 수 있습니다.
Keras API에는 겹치는 시간 데이터의 일괄 처리를 생성하는
TimeSeriesGenerator라는 내장 클래스가 있습니다. 이 클래스는 보폭,
기록 길이 등과 같은 시계열 매개변수와 함께 동일한 간격으로 수집된 일련의 데이터 포인트를 가져와 학습/검증을 위한 배치를 생성합니다.
그래서, 우리의 사용 사례에 대해
6일 분량의 과거 데이터로부터 예측하는 법을 배우고 미래의 어느 시점(예를 들어
1일)에 값을 예측하고 싶다고 가정해 보겠습니다.
이 경우 길이는
6일(24x6x6)의
10분 시간 단계 수치인
864와 같습니다.
마찬가지로 습도,
온도,
압력 등의 과거 값에서 배우려고 합니다.
즉,
모든 레이블에 대해 특성당
864개의 값이 있습니다.
우리의 데이터 세트에는 총
28개의 특성이 있습니다.
임시 시퀀스를 생성할 때 생성기는 매번
6일 분량의 데이터로 구성된 배치를 반환하도록 구성됩니다.
보다 현실적인 시나리오를 만들기 위해 미래의 하루 사용량을 예측하기로 선택하고(다음
10분 시간 간격과 반대)
미래에 대상 벡터가
144개의 타임스텝(24x6x1)
값 세트가 되도록 다음과 같은 방식으로 테스트 및 학습 데이터 세트를 준비합니다.
자세한 내용은 노트북 섹션
2: 데이터 세트 정규화 및 준비를 참조하세요.
입력 세트의 모양은 (samples, timesteps,
input_dim) [https://keras.io/layers/recurrent/]여야 합니다.
모든 배치에 대해
6일 분량의 데이터,
즉
864개 행이 있습니다.
배치 크기는 그래디언트 업데이트가 발생하기 전에 샘플 수를 결정합니다.

조정 매개변수의 전체 목록은 여기를 참조하십시오.
모델 학습
LSTM은
BPTT(Backpropogation through time)라는 개념을 사용하여 신경망의 장기 종속성 문제를 해결할 수 있습니다.
BPTT에 대한 자세한 내용은 여기를 참조하십시오.
LSTM 네트워크를 학습하기 전에 네트워크 품질을 결정하는
Keras에서 제공하는 몇 가지 주요 매개변수를 이해해야 합니다.
1. Epochs: 데이터가 신경망에 전달되는 횟수
2. 에포크당 단계:
학습 에포크가 완료된 것으로 간주되기 전의 배치 반복 횟수
3. 활성화:
사용할 활성화 기능을 설명하는 계층
4. 옵티마이저:
Keras는 내장 옵티마이저를 제공합니다.

GPU의 속도와 성능을 활용하기 위해
LSTM의
CUDNN 구현을 사용합니다.
우리는 또한 임의로 많은 수의 에포크를 선택했습니다.
이는 최상의 모델 적합성을 찾기 위해 데이터가 가능한 한 많은 반복을 거치도록 하기 때문입니다.
단위 수에 관해서는
28개의 기능이 있으므로
32개부터 시작합니다.
몇 번의 반복 후에
128개를 사용하면 괜찮은 결과를 얻을 수 있다는 것을 알았습니다.
에포크 수를 선택할 때는 과소적합을 피하기 위해 높은 수를 선택하는 것이 좋습니다.
과적합 문제를 피하기 위해
Keras API에서 내장 콜백을 사용할 수 있습니다.
특히
EarlyStopping. EarlyStopping은
모니터링된 양이 개선을 멈췄을 때 모델 학습을 중지합니다.
우리의 경우 모니터링된 수량으로
loss를 사용하고
50 epoch 동안
1e-5의 감소가 없을 때 모델은 학습을 중지합니다.
Keras에는
regularizer가 내장되어 있습니다.
(weighted, dropout) 매개변수의 원활한 분포를 보장하기 위해 네트워크에 불이익을 주어 네트워크가 유닛 간에 전달되는 컨텍스트에 너무 많이 의존하지 않도록 합니다.
네트워크의 레이어는 아래 이미지를 참조하십시오.
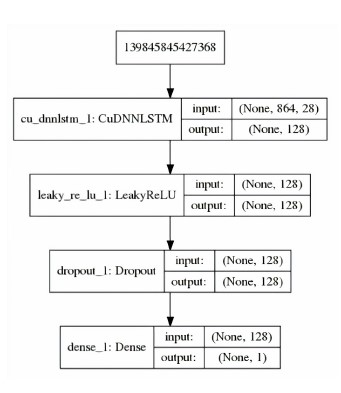
한 레이어의 출력을 다른 레이어로 보내기 위해서는 활성화 함수가 필요합니다.
이 경우 이전 제품인
Rectifier Linear Unit 또는 Relu의 더 나은 변형인 LeakyRelu를 사용합니다.
Keras는 손실을 줄이고 에포크에 걸쳐 반복적으로 가중치를 업데이트하기 위한 다양한 옵티마이저를 제공합니다.
옵티마이저의 전체 목록은 여기를 참조하세요.
우리는 확률적 경사하강법의
Adam 버전을 선택합니다.
옵티마이저의 중요한 파라미터는
learning_rate로,
모델의 품질을 크게 좌우할 수 있습니다.
학습률에 대한 자세한 내용은 여기에서 확인할 수 있습니다.
0.001(기본값),
0.01, 0.1 등 다양한 값으로 실험한 결과
0.00144가 학습 속도 및 최소 손실 측면에서 최고의 모델 성능을 제공한다는 것을 발견했습니다.
학습률을 최적의 값으로 조정하기 위해
LearningRateSchedular 콜백을 사용할 수도 있습니다. MLflow를 사용하여 여러 모델 실행에서 결과를 추적하고 비교했습니다.
MLflow를 사용한 모델 평가 및 로깅
보시다시피 Keras의
LSTM 구현은 꽤 많은 하이퍼파라미터를 사용합니다.
가장 적합한 모델을 찾으려면 단위,
에포크 등과 같은 다양한 하이퍼파라미터로 실험해야 합니다.
또한 과거 모델 실행을 비교하고 시간 경과에 따른 모델 동작과 데이터 변경을 측정하고 싶을 것입니다.
MLflow는 위의 작업과 그 이상을 수행할 수 있는 사용하기 쉬운
UI가 있는 훌륭한 도구입니다.
여기에서
MLflow를 사용하여
Keras 및
TensorFlow로 개발하고,
MLflow 실행을 기록하고,
시간 경과에 따른 실험을 추적하는 것이 얼마나 쉬운지 확인할 수 있습니다.
데이터 과학자는 MLflow를 사용하여 다양한 모델 메트릭과 추가 시각화 및 아티팩트를 추적하여 프로덕션에 배포해야 하는 모델을 결정할 수 있습니다.
그들은 가장 최적의 모델에 대한 결론을 내릴 때까지 두 개 이상의 모델 실행을 비교하여 다양한 초매개변수의 영향을 이해할 수 있습니다.
그러면 데이터 엔지니어는 선택한 모델 뿐만 아니라 운영 중인 새 데이터에 적용할 학습에 사용되는 라이브러리 버전도 쉽게 검색할 수 있습니다.
최종 모델은
python_function flavor로
지속할 수 있습니다.
그런 다음
Apache Spark UDF로
사용할 수 있으며,
이
UDF는
Spark 클러스터에 업로드되면 향후 데이터의 점수를 매기는 데 사용됩니다.
여기에서
MLflow에서 지원하는 모델 버전의 전체 목록을 찾을 수 있습니다.
요약
l LSTM은 미래 발생을 예측하기 위해 과거 값에서 학습하는 데 사용할 수 있습니다.
시계열에 대한
LSTM은 고전적인 접근 방식에서 만들어진 특정 가정을 하지 않으므로 시계열 문제를 모델링하고 여러 입력 간의 비선형 종속성을 더 쉽게 학습할 수 있습니다.
l LSTM
네트워크에 입력하기 전에 일련의 이벤트를 생성할 때 입력에서 레이블을 지연시키는 것이 중요하므로
LSTM 네트워크가 과거 데이터에서 학습할 수 있습니다.
Keras의
TimeSeriesGenerator 클래스를 사용하면 시차 데이터 세트를 신경망에 공급하기 전에 다양
l LSTM에는 예측 품질을 결정하는 데 필수적인
Epoch, 배치 크기 등과 같은 일련의 조정 가능한 하이퍼파라미터가 있습니다.
학습률은 모델 가중치가 업데이트되는 방식과 모델이 학습하는 속도를 제어하는 중요한 하이퍼파라미터입니다.
최상의 모델 성능을 얻기 위해서는 최적의 학습률 값을 결정하는 것이 매우 중요합니다.
학습률을 최적의 값으로 조정하려면
LearingRateSchedular 콜백 매개변수를 사용하는 것이 좋습니다.
l Keras는 해결하려는 문제 유형과 관련하여 사용할 다양한 최적화 프로그램을 제공합니다.
일반적으로 아담은 잘하는 경향이 있습니다.
MLflow UI를 사용하여 사용자는 모델 실행을 나란히 비교하여 최상의 모델을 선택할 수 있습니다.
l 시계열의 경우
LSTM 네트워크가 올바른 이벤트 시퀀스에서 패턴을 학습할 수 있도록 데이터의 시간성을 유지하는 것이 중요합니다.
따라서 테스트 및 검증 세트를 생성할 때와 모델을 피팅할 때 데이터를 섞지 않는 것이 중요합니다.
l 모든 머신 러닝 접근 방식과 마찬가지로
LSTM은 잘못된 피팅에 영향을 받지 않으므로
Keras에
EarlyStopping 콜백이 있습니다.
어느 정도의 직관력과 올바른 콜백 매개변수를 사용하면 하이퍼 매개변수를 조정하는 데 너무 많은 노력을 들이지 않고도 적절한 모델 성능을 얻을 수 있습니다.
l RNN,
특히
LSTM은 많은 양의 데이터가 제공될 때 가장 잘 작동합니다.
따라서 사용할 수 있는 데이터가 거의 없으면 숨겨진 계층이 몇 개인 더 작은 네트워크로 시작하는 것이 좋습니다.
데이터가 작을수록 사용자는 모든 에포크에 더 많은 데이터 배치를 제공할 수 있으므로 더 나은 결과를 얻을 수 있습니다.