





딥 러닝을 위한 전이 학습에 대한 간단한 소개
전이 학습은 작업을 위해 개발된 모델이 두번째 작업의 모델의 시작점으로 재사용되는 머신러닝 방법입니다.
신경망 모델을 개발하는 데에는 방대한 계산과 인력, 시간이 필요하기 때문에 사전 학습된 모델을 컴퓨터 비전 및 자연어 처리 작업의 시작점으로 사용하는 것이 일반적입니다.
이 글에서는 전이 학습을 사용하여 학습 속도를 높이고 딥 러닝 모델의 성능을 향상시키는 방법을 알아볼 것입니다.
글의 요점은 다음과 같습니다 :
- 어떤 전이 학습을 어떻게 사용하는지.
- 딥 러닝에서 전이 학습의 일반적인 예.
- 자신의 예측 모델링 문제에 대해 전이 학습을 사용하는 경우.
컴퓨터 비전을 위한 딥 러닝과 단계별 자습서 및 모든 예제에 대한 Python 소스 코드 파일을사용하여 프로젝트를 시작할 수 있습니다.
컴퓨터 비전에서 전이 학습을 사용하는 방법에 대한 예제는 다음 게시물을 참조하시면 됩니다.

Mike’s Birds의 딥 러닝 사진으로 전이 학습
전이 학습이란 무엇입니까?
전이 학습은 한 작업에 대해 학습된 모델이 두 번째 관련 작업에서 다시 사용되는 머신러닝 기술입니다. 전이 학습은 다중 과제 학습 및 concept drift와 같은 문제와 관련이 있으며 딥 러닝을 위한 연구 영역이 아닙니다.
그럼에도 불구하고 전이 학습은 딥 러닝 모델을 훈련시키는 데 필요한 막대한 리소스 또는 딥 러닝 모델을 훈련시키는 크고 도전적인 데이터 세트를 감안할 때 딥 러닝에서 인기가 있습니다.
전이 학습은 첫번째 작업에서 학습한 모델 특징이 일반적인 경우에만 딥 러닝에서 작동합니다.
전이 학습에서는 먼저 기본 데이터 집합 및 작업에 대해 기본 네트워크를 학습한 다음 학습된 특징을 용도를 변경하거나 두 번째 대상 네트워크로 이전하여 대상 데이터 세트 및 작업에 대해 학습합니다. 이 프로세스는 기능이 일반적인 경우 작동하는 경향이 있으며, 이는 기본 작업에만 국한된 것이 아니라 기본 작업과 대상 작업 모두에 적합함을 의미합니다.
이것은 다르지만 연관되어 있는 작업에 모델을 적용함으로써 가능한 모델(모델 편향)의 범위가 유익한 방식으로 좁혀지는 것입니다.
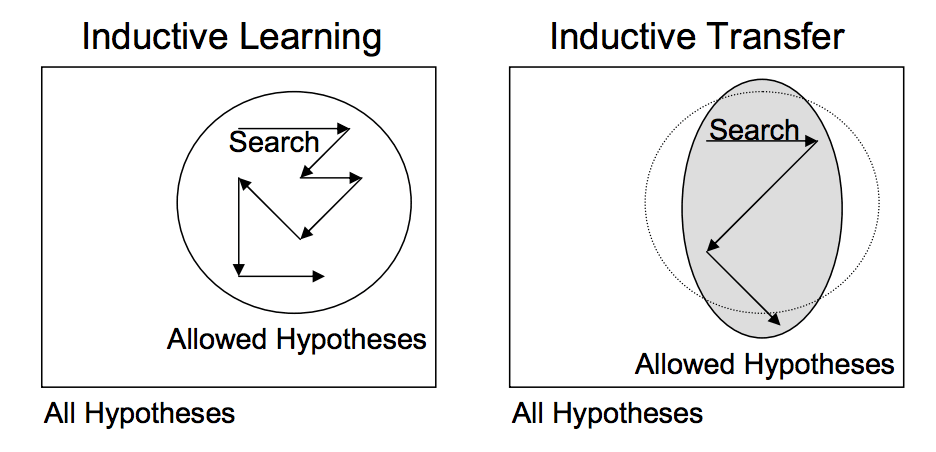
“전이 학습”에서 가져온 귀납적인 전이의 묘사
자신의 예측 모델링 문제에 대해 전이 학습을 사용할 수 있습니다.
두 가지 일반적인 접근 방식은 다음과 같습니다.
- 모델 접근 방식 개발
- 사전 학습된 모델 접근 방식
모델 접근 방식 개발
- 소스 작업을 선택합니다. 입력 데이터, 출력 데이터 또는 입력에서 출력 데이터로의 매핑 중에 학습된 개념에 일부 관계가 있는 많은 데이터를 사용하여 예측 모델링 문제를 선택해야 합니다.
- 소스 모델을 개발합니다. 다음으로 첫번째 작업에 대한 숙련된 모델을 개발해야 합니다. 일부 특징에 대해 학습이 수행되었는지 확인하기 위해 모델이 원래의 모델보다 우수해야 합니다.
- 모델 재사용. 그런 다음 원본 작업에 대한 모델 적용을 두 번째 관심 작업의 모델의 시작점으로 사용할 수 있습니다. 여기에는 사용되는 모델링 기술에 따라 모델의 전체 또는 일부를 사용하는 것이 포함될 수 있습니다.
- 모델 조정. 선택적으로, 모델은 목표로 하는 작업에 적용가능한 입출력 쌍 데이터에 대해 적용하거나 정제할 필요가 있습니다.
사전 학습된 모델 접근 방식
- 소스 모델을 선택합니다. 미리 학습된 소스 모델은 사용 가능한 모델에서 선택됩니다. 많은 연구 기관은 선택할 후보 모델 풀에 포함될 수 있는 크고 까다로운 데이터 세트에 대한 모델을 출시합니다.
- 모델 재사용. 그런 다음 미리 학습된 모델을 두 번째 관심 있는 작업의 모델의 시작점으로 사용할 수 있습니다. 여기에는 사용되는 모델링 기술에 따라 모델의 전체 또는 일부를 사용하는 것이 포함될 수 있습니다.
- 모델 조정. 선택적으로, 모델은 목표로 하는 작업에 적용가능한 입출력 쌍 데이터에 대해 적용하거나 정제할 필요가 있습니다.
이 두 번째 유형의 전이 학습은 딥 러닝 분야에서 일반적입니다.
딥 러닝을 통한 전이 학습의 예
딥 러닝 모델을 사용한 전이 학습의 두 가지 일반적인 예를 통해 이것을 구체적으로 만들어 봅시다.
이미지 데이터로 학습 전송
이미지 데이터를 입력으로 사용하는 예측 모델링 문제로 이전 학습을 수행하는 것이 일반적입니다.
이것은 사진 또는 비디오 데이터를 입력하는 예측 작업일 수 있습니다.
이러한 유형의 문제의 경우 ImageNet 1000 클래스 사진 분류 경쟁과 같은 크고 까다로운 이미지 분류 작업을 위해 미리 학습된 딥 러닝 모델을 사용하는 것이 일반적입니다.
이 경쟁을 위한 모델을 개발하고 잘하는 연구 기관은 종종 재사용을 위해 허용된 라이센스 하에 최종 모델을 출시합니다. 이러한 모델은 최신 하드웨어에서 학습하는 데 며칠 또는 몇 주가 걸릴 수 있습니다.
이러한 모델은 이미지 데이터를 입력으로 기대하는 새 모델에 직접 다운로드하여 통합할 수 있습니다.
이 유형의 모델의 세 가지 예는 다음과 같습니다.
더 많은 예제는 더 많은 사전 학습된 모델이 공유되는 Caffe Model Zoo를 참조하세요.
이 접근 방식은 이미지가 많은 사진 모음에서 학습되고 모델이 비교적 많은 수의 클래스에 대한 예측을 수행해야하기 때문에 모델이 문제를 잘 수행하기 위해 사진에서 기능을 추출하는 방법을 효율적으로 학습해야 하기 때문에 효과적입니다.
시각 인식을 위한 컨볼루션 신경망에 대한 스탠포드 과정에서 저자는 새 모델에서 사용할 사전 학습된 모델의 양을 신중하게 선택해야 한다고 말합니다.
[컨볼루션 신경망] 기능은 초기 계층에서는 더 일반적이며 이후 계층에서는 원본 데이터 세트에 따라 다릅니다.
— 이전 학습, 시각적 인식을 위한 CS231n 컨볼루션 신경망
Transfer Learning with Language Data언어 데이터로 학습 전송
텍스트를 입력 또는 출력으로 사용하는 자연어 처리 문제로 전이 학습을 수행하는 것이 일반적입니다.
이러한 유형의 문제의 경우 유사한 의미를 가진 다른 단어가 유사한 벡터 표현을 갖는 고차원 연속 벡터 공간에 단어를 매핑하는 단어 임베딩이 사용됩니다.
효율적인 알고리즘은 이러한 분산 단어 표현을 학습하기 위해 존재하며 연구 조직은 허용 라이센스하에 매우 큰 텍스트 문서 모음에서 훈련된 사전 훈련 된 모델을 릴리스하는 것이 일반적입니다.
이 유형의 모델의 두 가지 예는 다음과 같습니다.
이러한 분산 단어 표현 모델은 단어를 입력으로 해석하거나 모델에서 출력으로 단어를 생성하는 딥 러닝 언어 모델에 다운로드하여 통합할 수 있습니다.
전이 학습은 언제 사용합니까?
전이 학습은 최적화이며 시간을 절약하거나 더 나은 성능을 얻는 지름길입니다.
일반적으로 모델이 개발되고 평가될 때까지 도메인에서 전이 학습을 사용하는 것이 이점이 있다는 것은 분명하지 않습니다.
Lisa Torrey와 Jude Shavlik은 그들의 저서 기계 학습 응용 프로그램 및 동향에 대한 연구 핸드북: 알고리즘, 방법 및 기술에서 전이학습을 사용할 때 3가지 이점을 설명합니다.
- Higher start. 소스 모델의 초기 기술(모델을 구체화하기 전에)은 전이학습을 사용하지 않을 때보다 높습니다.
- Higher slope. 소스 모델을 학습하는 동안 기술 향상의 속도는 전이학습을 사용하지 않을 때보다 높습니다.
- Higher asymptote. 학습된 모델의 수렴된 기술은 전이학습을 사용하지 않을 때보다 낫습니다.
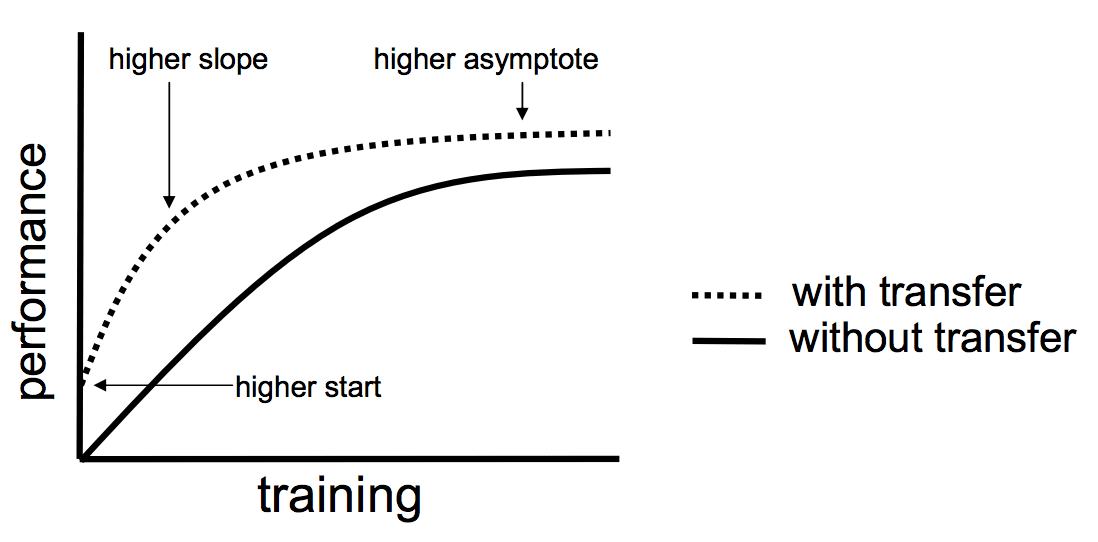
Three ways in which transfer might improve learning.
Taken from “Transfer Learning”.
이상적으로는 전이 학습의 성공적인 적용으로 3가지 이점을 모두 누릴 수 있습니다.
풍부한 데이터로 관련 작업을 식별할 수 있고 해당 작업에 대한 모델을 개발하고 자신의 문제에 재사용할 수 있는 리소스가 있거나 사용자 고유의 모델의 시작점으로 사용할 수 있는 사전 학습된 모델이 있는지 여부를 시도하는 방법입니다.
데이터가 많지 않은 일부 문제에서는 전이 학습을 통해 전이 학습이 없으면 개발할 수 없는 숙련된 모델을 개발할 수 있습니다.
소스 데이터 또는 소스 모델의 선택은 공개적인 문제이며 경험을 통해 개발된 도메인 전문 지식 및/또는 직관이 필요할 수 있습니다.