





머신러닝 적용사례 제 7장. 대규모 지리 공간 데이터 처리
기술의 발전으로 인해 시기 적절하고 정확한 지리 공간 데이터에 대한 시장이 활성화되었습니다.
매일 수십억 개의 핸드헬드 및
IoT 장치와 수천 개의 항공 및 위성 원격 감지 플랫폼이 수백 엑사바이트의 위치 인식 데이터를 생성합니다.
머신러닝의 발전과 결합된 지리 공간 빅 데이터의 붐으로 여러 산업 분야의 조직이 새로운 제품과 기능을 구축할 수 있습니다.
예를 들어 많은 회사에서 매핑 및 현장 답사와 같은 현지화된 드론 기반 서비스를 제공합니다(Intelligent
Cloud 및
Intelligent Edge용으로 개발 참조). 지리정보 데이터 분야에서 빠르게 성장하는 또 다른 산업은 자율주행차입니다.
신생 기업과 기존 기업은 모두 차량 센서에서 상황에 맞는 대규모 지리 데이터를 축적하여 자율 주행 자동차의 차세대 혁신을 실현하고 있습니다(참조
Databricks는 이동성 데이터 생태계를 만들려는
wejo의 야망을 뒷받침합니다).
소매업체와 정부 기관도 지리 공간 데이터를 사용하려고 합니다.
예를 들어,
보행자 통행량 분석(Building
Foot-Traffic Insights Data Set 참조)은 새 매장을 열기에 가장 좋은 위치를 결정하거나 공공 부문에서 도시 계획을 개선하는 데 도움이 될 수 있습니다.
지리 공간 데이터에 대한 이러한 모든 투자에도 불구하고 많은 도전이 존재합니다.
대규모 지리 공간 분석 과제
첫 번째 과제는 스트리밍 및 배치 애플리케이션의 규모를 처리하는 것입니다.
애플리케이션에 필요한 지리 공간 데이터와
SLA의 급증은 기존의 저장 및 처리 시스템을 압도합니다.
고객 데이터는 데이터 볼륨,
속도,
저장 비용 및 엄격한 schema-on-write 강제와 같은 문제로 인해 여러해 동안 수직으로 확장된 지리 데이터베이스에서 데이터 레이크로 유출되었습니다.
기업은 지리 공간 데이터에 투자했지만 다운스트림 분석을 위해 이러한 크고 복잡한 데이터 세트를 준비할 수 있는 적절한 기술 아키텍처를 갖춘 기업은 거의 없습니다.
또한 확장된 데이터가 고급 적용 사례에 필요한 경우가 많다는 점을 감안할 때 대부분의
AI 주도 이니셔티브는 파일럿에서 프로덕션 단계로 넘어가는 데 실패하고 있습니다.
다양한 공간 형식과의 호환성은 두 번째 과제입니다.
위치 정보가 수집될 수 있는 부수적인 데이터 소스뿐만 아니라 수십 년에 걸쳐 확립된 다양한 특수 지리 공간 형식이 있습니다.
n GeoJSON,
KML, Shapefile 및 WKT와 같은 벡터 형식
n ESRI
Grid, GeoTIFF, JPEG 2000 및 NITF와 같은 래스터 형식
n AIS
및
GPS 장치에서 사용하는 것과 같은 항해 표준
n PostgreSQL/PostGIS와 같은
JDBC/ODBC 연결을 통해 액세스할 수 있는 지오데이터베이스
n Hyperspectral,
Multispectral, Lidar 및
n 레이더 플랫폼
n WCS,
WFS, WMS 및
WMTS와 같은
OGC 웹 표준
n 지오태깅된 로그,
사진,
비디오 및 소셜 미디어
n 위치 참조가 있는 비정형 데이터
이 블로그 게시물에서는 Databricks 통합 데이터 분석 플랫폼을 사용하여 위에 나열된 두 가지 주요 과제를 처리하기 위한 일반적인 접근 방식에 대한 개요를 제공합니다.
이것은 대량의 지리 공간 데이터 작업에 대한 블로그 게시물 시리즈의 첫 번째 부분입니다.
Databricks를 사용하여 지리 공간 워크로드 확장
Databricks는 전 세계 수천 명의 고객이 사용하는 빅 데이터 분석 및 머신러닝을 위한 통합 데이터 분석 플랫폼을 제공합니다.
Apache Spark™, Delta Lake 및 MLflow를 기반으로 하며 타사 및 사용 가능한 라이브러리 통합의 광범위한 에코시스템을 갖추고 있습니다.
Databricks UDAP는
프로덕션 워크로드에 대해 엔터프라이즈급 보안,
지원,
안정성 및 성능을 대규모로 제공합니다.
지리 공간 워크로드는 일반적으로 복잡하며 모든 적용 사례에 맞는 하나의 라이브러리가 없습니다.
Apache Spark는 기본적으로 지리 공간 데이터 유형을 제공하지 않지만 기업뿐만 아니라 오픈 소스 커뮤니티는 공간 라이브러리를 개발하기 위해 많은 노력을 기울였으며 결과적으로 선택할 수 있는 옵션의 바다가 생겼습니다.
일반적으로 공간 조인 또는 최근접 이웃과 같은 지리 공간 작업을 확장하기 위한 세 가지 패턴이 있습니다.
1. 지리 공간 분석을 위해
Apache Spark를 확장하는 특수 제작 라이브러리 사용.
GeoSpark, GeoMesa, GeoTrellis 및 Rasterframes는 고객이 사용하는 이러한 라이브러리 중 일부입니다.
이러한 프레임워크는 종종 여러 언어 바인딩을 제공하고,
비정형화된 접근 방식보다 훨씬 더 나은 확장성과 성능을 제공하지만 학습 곡선도 함께 제공될 수 있습니다.
2. GeoPandas,
Geospatial Data Abstraction Library(GDAL) 또는 Java Topology Service(JTS)와 같은 단일 노드 라이브러리를
Spark DataFrames를
사용하여 분산 방식으로 처리하기 위해 임시 사용자 정의 함수(UDF)에 래핑합니다.
이것은 많은 코드 재작성 없이 기존 워크로드를 확장하기 위한 가장 간단한 접근 방식입니다.
그러나 본질적으로 리프트 앤 시프트가 더 많기 때문에 성능 단점이 발생할 수 있습니다.
3. 그리드 시스템으로 데이터를 인덱싱하고 생성된 인덱스를 활용하여 공간 연산을 수행하는 것은 대규모 또는 계산적으로 제한된 워크로드를 처리하기 위한 일반적인 접근 방식입니다.
S2, GeoHex 및
Uber의
H3는 이러한 그리드 시스템의 예입니다.
그리드는 고정된 식별 가능한 셀 세트로 폴리곤 또는 포인트와 같은 지리적 특징을 근사하므로 비용이 많이 드는 지리 공간 작업을 모두 피할 수 있으므로 훨씬 더 나은 크기 조정 동작을 제공합니다.
구현자는 다소 손실이 있지만 성능이 더 좋을 수 있는 단일 정확도로 고정된 그리드 또는 성능은 낮지만 손실을 완화할 수 있는 다중 정확도를 가진 그리드 중에서 결정할 수 있습니다.
다음 예는 일반적으로 여기에서 찾을 수 있는
NYC 택시 승차/하차 데이터 세트를 중심으로 합니다.
지오메트리가 있는
NYC Taxi Zone 데이터도 폴리곤 세트로 사용됩니다.
이 데이터에는
NYC의
5개 자치구와 이웃에 대한 다각형이 포함되어 있습니다.
이 노트북은 초기
CSV 파일을 안정적이고 성능이 뛰어난 데이터 원본인
Delta Lake 테이블로 변환하기 위해 수행되는 준비 및 정리 과정을 안내합니다.
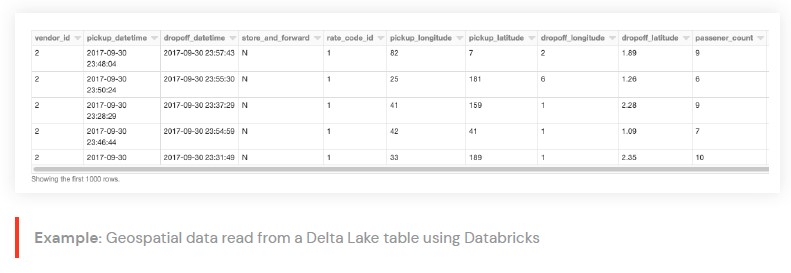
우리의 기본 DataFrame은
Databricks를 사용하여
Delta Lake 테이블에서 읽은 택시 승차/하차 데이터입니다.

Apache Spark용 지리 공간 라이브러리를 사용한 지리 공간 작업
지난 몇 년 동안 지리 공간 분석을 위한 Apache Spark의 기능을 확장하기 위해 여러 라이브러리가 개발되었습니다.
이러한 프레임워크는 일반적으로 적용되는
UDT(사용자 정의 유형)
및
UDF(함수)를 일관된 방식으로 등록해야 하므로 사용자와 팀이 임시 공간 논리를 작성해야 하는 부담을 덜어줍니다.
이 블로그 게시물에서는 다양한 기능을 강조하기 위해 선택한 여러 공간 프레임워크를 사용합니다.
강조 표시된 프레임워크 외에도 공간 워크로드를 처리하기 위해
Databricks와 함께 사용할 수 있는 다른 프레임워크가 있다는 것을 알고 있습니다.
이전에는 기본 데이터를
DataFrame에 로드했습니다.
이제 위도/경도 속성을 포인트 지오메트리로 변환해야 합니다.
이를 수행하기 위해
UDF를 사용하여 분산 방식으로
DataFrame에 대한 작업을 수행합니다.
이러한 프레임워크를 클러스터에 추가하는 방법과
UDF 및
UDT를 등록하기 위한 초기화 호출에 대한 자세한 내용은 블로그 끝에 제공된 노트북을 참조하십시오.
우선 클러스터에
GeoMesa를 추가했습니다.
이 프레임워크는 특히 벡터 데이터를 처리하는 데 능숙합니다.
수집을 위해
JTS와
Spark SQL의 통합을 주로 활용하므로 등록된
JTS 기하학 클래스로 쉽게 변환하고 사용할 수 있습니다.
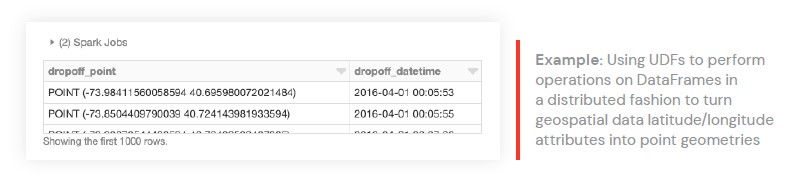
위도와 경도가 주어지면
Point 기하 객체를 생성하는
st_makePoint 함수를 사용할 것입니다.
함수는
UDF이므로 열에 직접 적용할 수 있습니다.

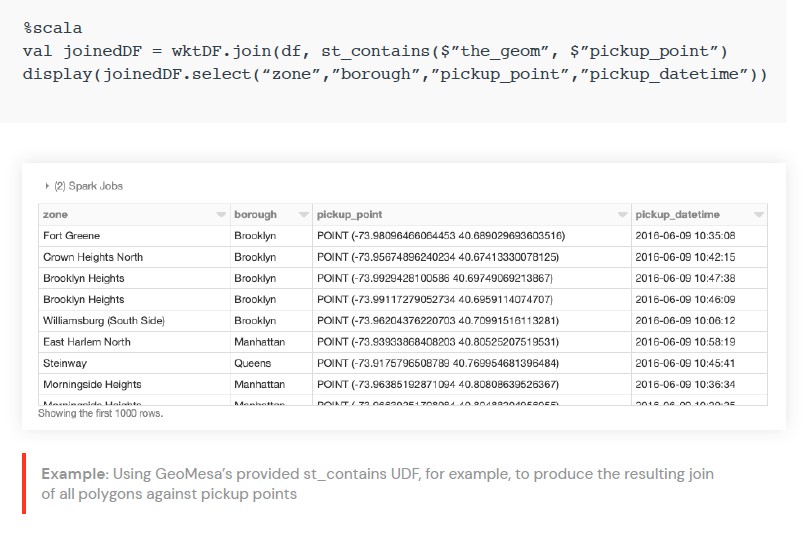
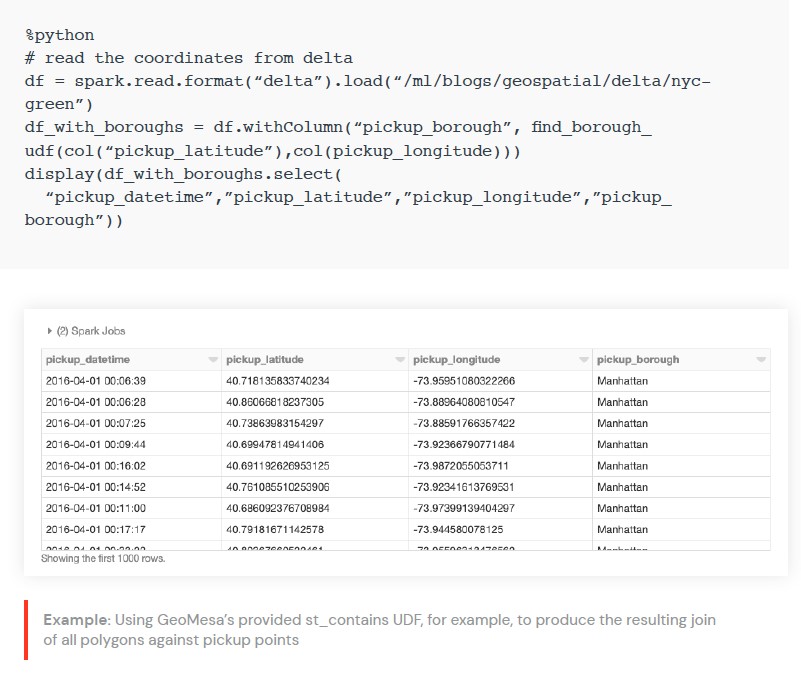
우리는 또한 분산 공간 조인을 수행할 수 있습니다. 이 경우
GeoMesa에서 제공하는
st_contains UDF를
사용하여 픽업 지점에 대한 모든 폴리곤의 결과 조인을 생성합니다.
UDF에서 단일 노드 라이브러리 래핑
목적에 맞게 구축된 분산 공간 프레임워크를 사용하는 것 외에도 기존 단일 노드 라이브러리를 임시
UDF에 래핑하여 분산 방식으로
DataFrame에서 지리 공간 작업을 수행할 수도 있습니다.
이 패턴은 모든
Spark 언어 바인딩(Scala,
Java, Python, R 및 SQL)에서 사용할 수 있으며 최소한의 코드 변경으로 기존 워크로드를 활용하기 위한 간단한 접근 방식입니다.
단일 노드 예를 보여주기 위해
NYC 자치구 데이터를 로드하고 지오팬더를 사용하여 자치구에 각
GPS 위치를 할당하기 위해
point-in-polygon 작업에 대해 UDF find_borough(…)를 정의해 보겠습니다.
더 나은 성능을 위해 벡터화된
UDF를 사용하여 이 작업을 수행할 수도 있습니다.

이제 UDF를 적용하여 각 픽업 지점에 자치구 이름을 할당하는
Spark DataFrame에
열을 추가할 수 있습니다.
공간 인덱싱을 위한 그리드 시스템
지리 공간 작업은 본질적으로 계산 비용이 많이 듭니다.
포인트 인 폴리곤,
공간 조인,
가장 가까운 이웃 또는 경로에 대한 스냅은 모두 복잡한 작업을 포함합니다.
그리드 시스템으로 인덱싱함으로써 지리 공간 작업을 완전히 피하고자 하는 것이 목표입니다.
이러한 접근 방식으로 대략적인 작업의 주의 사항과 함께 가장 확장 가능한 실행이 가능합니다.
다음은
H3의 간단한 예입니다.
H3로 공간 작업을 확장하는 것은 기본적으로
2단계 프로세스입니다.
첫 번째 단계는
UDF geoToH3(…)로 정의된 각 피처(포인트,
폴리곤,
…)에 대한
H3 인덱스를 계산하는 것입니다.
두 번째 단계는 공간 결합(폴리곤의 점,
k-최근접 이웃 등)과 같은 공간 작업에 이러한 인덱스를 사용하는 것입니다.
이 경우
UDF multiPolygonToH3(…)로
정의됩니다.


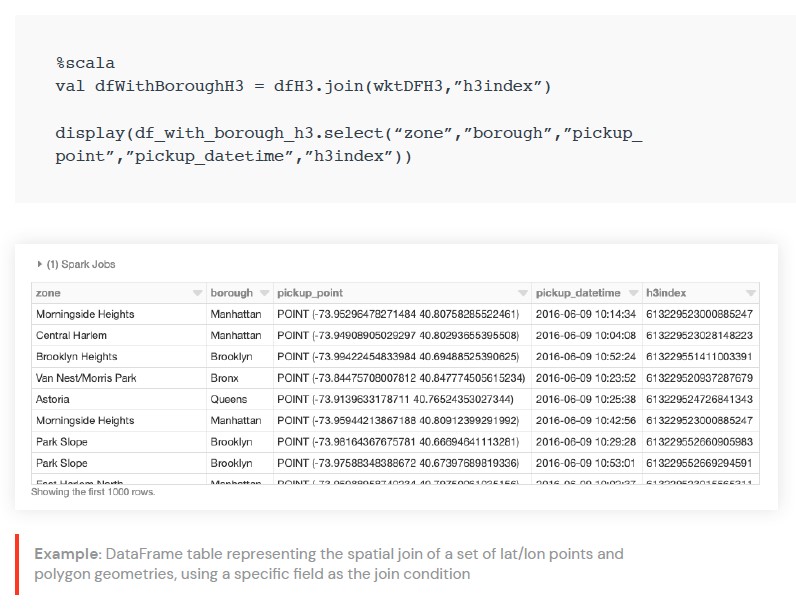
이제 이 두 UDF를
NYC 택시 데이터와 자치구 다각형 세트에 적용하여
H3 인덱스를 생성할 수 있습니다.

위도/경도 포인트 세트와 폴리곤 지오메트리 세트가 주어지면 이제
h3index 필드를 결합 조건으로 사용하여 공간 결합을 수행할 수 있습니다.
이러한 할당은 예를 들어 각 다각형에 속하는 포인트 수를 집계하는 데 사용할 수 있습니다.
일반적으로 수천 또는 수백만 개의 다각형과 일치해야 하는 수백만 또는 수십억 개의 점이 있으므로 확장 가능한 접근 방식이 필요합니다.
이 블로그에서는 다루지 않았지만 근사치가 충분하지 않을 때 공간 연산을 지원하기 위해 인덱싱에 사용할 수 있는 기술이 있습니다.
다음은 위도와 경도가 7(1.22km 가장자리 길이)의 해상도로 비닝되고 각 빈 내 집계된 수로 색상이 지정된 택시 하차 위치의 시각화입니다.
Databricks로 공간 형식 처리
지리 공간 데이터에는 속성에 의해 설명된 기능과 함께 지구의 물리적 위치 또는 범위에 대한 위도 및 경도와 같은 참조점이 포함됩니다.
선택할 수 있는 파일 형식이 많지만
Databricks를 사용한 읽기를 보여 주기 위해 몇 가지 대표적인 벡터 및 래스터 형식을 선택했습니다.
벡터 데이터
벡터 데이터는 x(경도),
y(위도)
좌표(도),
고도가 고려되는 경우
z(미터 단위 고도)에 저장된 세계의 표현입니다.
벡터 데이터의 세 가지 기본 기호 유형은 점,
선 및 다각형입니다.
Wellknown-text(WKT), GeoJSON 및 Shapefile은 아래에서 강조하는 벡터 데이터를 저장하는 데 널리 사용되는 형식입니다.
WKT로 저장된 지오메트리로
NYC Taxi Zone 데이터를 읽어봅시다.
반환하려는 데이터 구조는 블로그의 다른 곳에서 사용되는 것과 같은 다른
API 및 사용 가능한 데이터 소스로 표준화할 수 있는
DataFrame입니다.
st_geomFromWKT(…) UDF 호출을 통해 필드_geom에서 찾은 WKT 텍스트 콘텐츠를 해당
JTS Geometry 클래스로 쉽게 변환할 수 있습니다.

GeoJSON은 기능,
속성 및 공간 범위를 포함하여 다양한 지리 데이터 구조를 인코딩하기 위해 많은 오픈 소스
GIS 패키지에서 사용됩니다.
이 예에서는 워크플로에 따라 취한 접근 방식으로
NYC 자치구 경계를 읽습니다.
데이터가
JSON을 준수하므로
.option(“multiline”,”true”)이 있는 Databricks 내장
JSON 판독기를 사용하여 중첩된 스키마로 데이터를 로드할 수 있습니다.


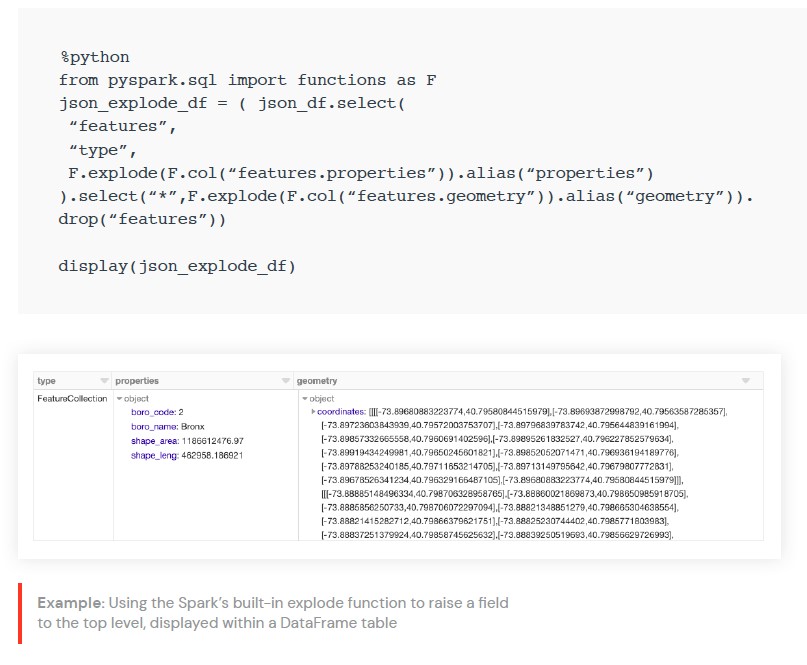
거기에서 Spark의 내장 폭발 기능을 사용하여 필드를 최상위 열까지 끌어올리도록 선택할 수 있습니다.
예를 들어,
기하학,
속성 및 유형을 가져온 다음
WKT 예제에서 볼 수 있는 것처럼 기하학을 해당
JTS 클래스로 변환할 수 있습니다.
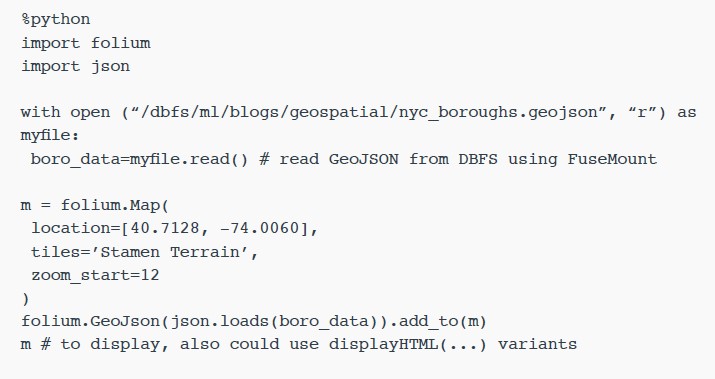
또한 기존 DataFrame을 사용하여 노트북 내에서
NYC Taxi Zone 데이터를 시각화하거나 공간 데이터를 렌더링하기 위한
Python 라이브러리인
Folium과 같은 라이브러리를 사용하여 데이터를 직접 렌더링할 수도 있습니다.
DBFS(Databricks File System)는
분산 스토리지 계층에서 실행되므로 코드가 친숙한 파일 시스템 표준을 사용하여 데이터 형식으로 작업할 수 있습니다.
DBFS에는 파일 읽기 및 쓰기 작업을 수행하는 로컬
API 호출을 허용하는
FUSE 마운트가 있어 대화형 렌더링을 위해 비분산
API로 데이터를 매우 쉽게 로드할 수 있습니다.
아래
Python open(…) 명령에서 “/dbfs/…” 접두사는
FUSE 마운트를 사용할 수 있도록 합니다.
Shapefile은
ESRI에서 개발한 인기 있는 벡터 형식으로 지리적 위치와 지리적 특징의 속성 정보를 저장합니다.
이 형식은 동일한 디렉토리에 저장된 공통 파일 이름 접두어(*.shp,
*.shx 및
*.dbf는 필수)가 있는 파일 모음으로 구성됩니다.
shapefile의 대안은
KML이며 고객도 사용하지만 간략하게 표시하지 않았습니다.
이 예에서는
NYC Building shapefile을
사용하겠습니다.
shapefile을 읽는 방법은 여러 가지가 있지만
GeoSpark를 사용한 예를 보여 드리겠습니다.
기본 제공
ShapefileReader는 rawSpatialDf DataFrame을 생성하는 데 사용됩니다.
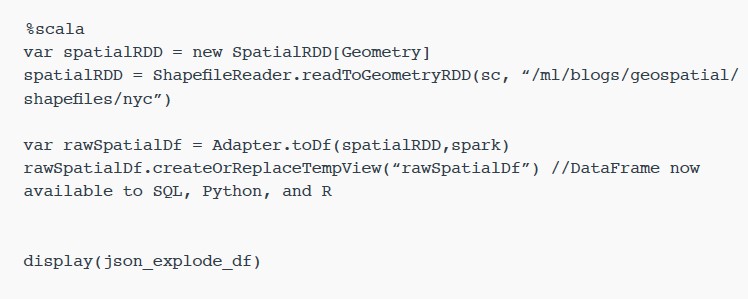
rawSpatialDf를 임시 보기로 등록하면
UDF를 적용하여
shapefile WKT를
Geometry로 변환하는 것을 포함하여
DataFrame과 함께 작동하는 순수한
Spark SQL 구문으로 쉽게 이동할 수 있습니다.

또한 NYC에서 가장 높은 건물을 차트로 표시하는 것과 같은 인라인 분석을 위해
Databricks의 기본 제공 시각화를 사용할 수 있습니다.
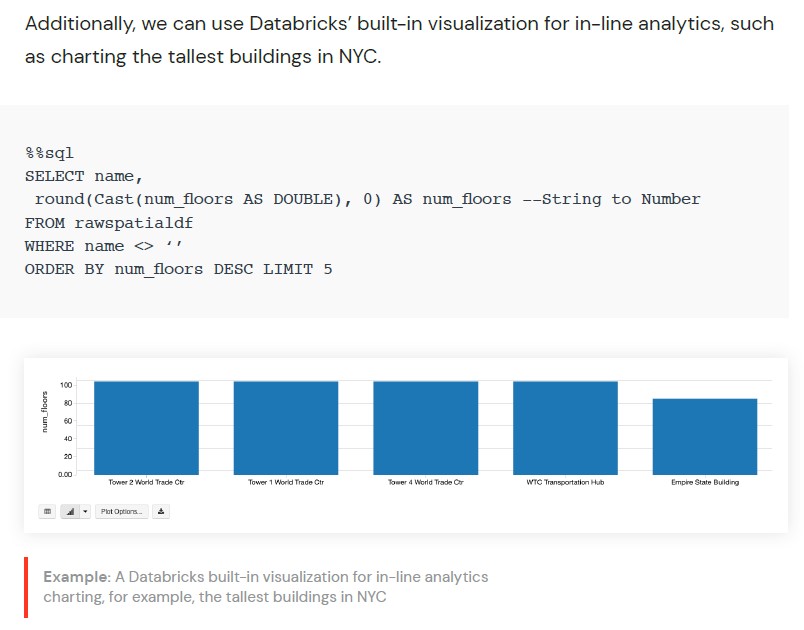
래스터 데이터
래스터 데이터는 행과 열(불연속 또는 연속)로 구성된 셀(또는 픽셀)
매트릭스에 기능 정보를 저장합니다.
위성 이미지,
사진 측량 및 스캔된 지도는 모든 유형의 래스터 기반 지구 관측(EO)
데이터입니다.
다음 Python 예제는
DataFrame 중심 공간 분석 프레임워크인
RasterFrames를 사용하여
GeoTIFF Landsat-8 이미지의 두
밴드(빨간색 및 근적외선)를 읽고 이를
Normalized Difference Vegetation Index로 결합합니다. 이 데이터를 사용하여
NYC 주변의 식물 건강을 평가할 수 있습니다.
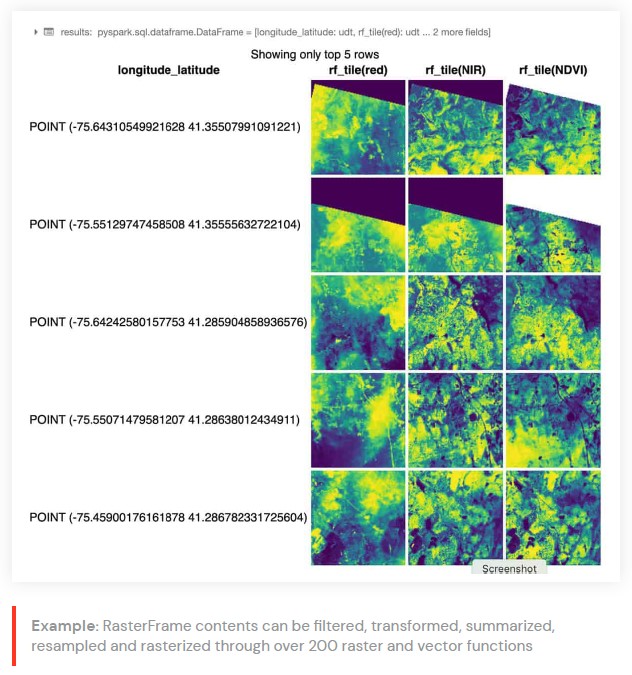
rf_ipython 모듈은
Databricks 내장
displayHTML(…) 명령을 사용하여 노트북 내에서 결과를 표시하는 빨간색, NIR 및 NDVI 타일 열이 색상 램프로 렌더링되는 아래와 같이 시각적으로 유용한 다양한 형식으로
RasterFrame 콘텐츠를 조작하는 데 사용됩니다.

RasterFrames는 맞춤형
Spark DataSource를
통해 다양한 서비스에서
GeoTIFF, JP2000, MRF 및 HDF를 비롯한 다양한 래스터 형식을 읽을 수 있습니다. 또한 벡터 형식
GeoJSON 및
WKT/WKB 읽기를 지원합니다.
RasterFrame 내용은 위의 예에서 사용된
st_reproject(…) 및 st_centroid(…)와 같은 200개 이상의 래스터 및 벡터 함수를 통해 필터링,
변환,
요약,
리샘플링 및 래스터화할 수 있습니다.
Python, SQL 및
Scala용 API와 Spark ML과의 상호 운용성을 제공합니다.
지리 데이터베이스
지리 데이터베이스는 소규모 데이터의 경우 파일 기반이거나 중간 규모 데이터의 경우
JDBC/ODBC 연결을 통해 액세스할 수 있습니다.
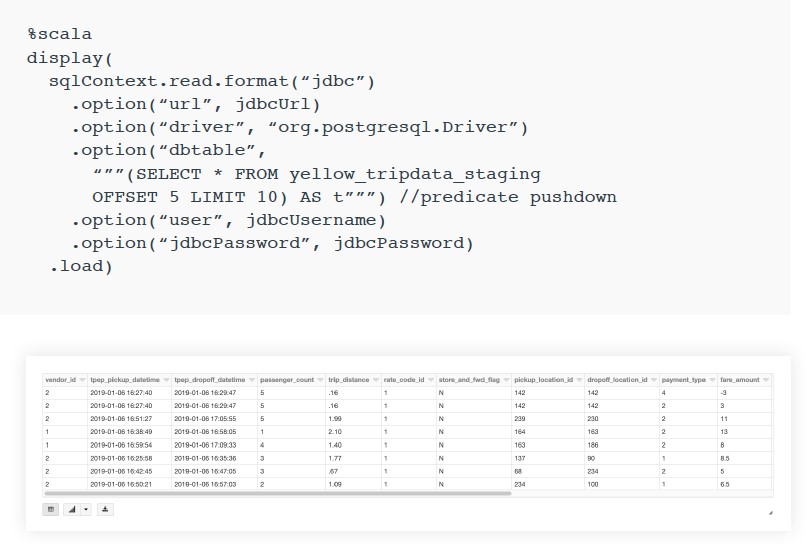
Databricks를 사용하여 기본 제공
JDBC/ODBC 데이터 원본으로 많은
SQL 데이터베이스를 쿼리할 수 있습니다.
PostgreSQL에 연결하는 방법은 아래와 같으며 일반적으로
PostGIS 확장을 적용하여 소규모 워크로드에 사용됩니다.
이러한 연결 패턴을 통해 고객은 기존 데이터베이스에 대한 액세스를 있는 그대로 유지할 수 있습니다.
Databricks에서 지리 공간 분석 시작하기
기업 및 정부 기관은 실행 가능한 통찰력을 도출하고 광범위하고 혁신적인 적용 사례를 제공하기 위해 엔터프라이즈 데이터 소스와 함께 공간 참조 데이터를 사용하려고 합니다.
이 블로그에서는
Databricks Unified Data Analytics Platform이 지리 공간 워크로드를 쉽게 확장하여 고객이 클라우드의 힘을 활용하여 방대한 크기의 데이터를 캡처,
저장 및 분석할 수 있는 방법을 시연했습니다.