Simulated annealing은 확률적 글로벌 검색 최적화 알고리즘입니다.
이는 검색 프로세스의 일부로 임의성을 사용한다는 것을 의미합니다. 따라서 알고리즘은 다른 로컬 검색 알고리즘이 제대로 작동하지 않는 비선형 목적 함수에 적합합니다.
확률적 hill climbing 로컬 검색 알고리즘과 마찬가지로 단일 솔루션을 수정하고 로컬 최적값을 찾을 때까지 검색 공간의 상대적으로 로컬 영역을 검색합니다. hill climbing 알고리즘과 달리 현재 작동하는 솔루션으로 더 나쁜 솔루션을 받아 들일 수 있습니다.
더 나쁜 솔루션을 수용 할 가능성은 검색 시작시 높게 시작하여 검색 진행에 따라 감소하여 알고리즘이 먼저 글로벌 최적 지역을 찾고 로컬 최적을 탈출 한 다음 최적 자체로 언덕을 올라갈 수있는 기회를 제공합니다.
이 자습서에서는 함수 최적화를 위한 Simulated annealing 최적화 알고리즘을 알아봅니다.
이 자습서를 완료하면 다음을 알 수 있습니다.
- Simulated annealing은 함수 최적화를 위한 확률적 전역 검색 알고리즘입니다.
- Python에서 시뮬레이션 된 annealing 알고리즘을 처음부터 구현하는 방법.
- Simulated annealing 알고리즘을 사용하고 알고리즘의 결과를 검사하는 방법
튜토리얼 개요
이 자습서는 다음과 같이 세 부분으로 나뉩니다.
- Simulated annealing
- Simulated annealing 구현
- Simulated annealing 작업 예제
Simulated annealing
Simulated annealing은 확률적 글로벌 검색 최적화 알고리즘입니다.
이 알고리즘은 금속을 고온으로 빠르게 가열 한 다음 천천히 냉각하여 강도를 높이고 작업하기 쉽게 만드는 야금의 annealing에서 영감을 얻었습니다.
annealing 공정은 먼저 고온에서 재료를 가열하여 원자가 많이 움직일 수 있도록 한 다음 천천히 열을 식혀 원자가 새롭고 안정적인 구성으로 떨어지도록 합니다.
뜨거울 때 물질의 원자는 더 자유롭게 움직일 수 있으며 무작위 운동을 통해 더 나은 위치에 정착하는 경향이 있습니다. 느린 냉각은 재료를 질서 정연한 결정 상태로 만듭니다.
— 128페이지, 최적화 알고리즘, 2019.
Simulated annealing 최적화 알고리즘은 확률적 hill climbing의 수정된 버전으로 생각할 수 있습니다.
확률적 hill climbing은 단일 후보 솔루션을 유지하고 검색 공간의 후보로부터 무작위이지만 제한된 크기의 단계를 수행합니다. 새 점이 현재 점보다 좋으면 현재 점이 새 점으로 바뀝니다. 이 프로세스는 고정된 반복 횟수 동안 계속됩니다.
시뮬레이션된 강화는 동일한 방식으로 검색을 실행합니다. 가장 큰 차이점은 현재 지점만큼 좋지 않은 새로운 포인트 (더 나쁜 포인트)가 때때로 받아 들여진다는 것입니다.
더 나쁜 점은 현재 솔루션보다 더 나쁜 솔루션을 수락할 가능성이 검색 온도와 솔루션이 현재 솔루션보다 얼마나 나쁜지의 함수인 확률 론적으로 받아 들여집니다.
알고리즘은 원래 후보 솔루션인 S를 새로 조정된 자식인 R로 대체할 시기를 결정하는 Hill-Climbing과 다릅니다. 특히 R이 S보다 나은 경우 평소와 같이 항상 S를 R로 바꿉니다. 그러나 R이 S보다 나쁘면 특정 확률로 S를 R로 바꿀 수 있습니다.
— 23페이지, 메타휴리스틱의 본질, 2011.
검색을 위한 초기 온도는 하이퍼파라미터로 제공되며 검색의 진행에 따라 감소합니다. 반복 횟수의 함수로서 온도를 계산하는 것이 일반적이지만, 초기 값으로부터 매우 낮은 값으로 검색하는 동안 온도를 감소시키기 위해 다수의 상이한 방식(annealing 스케줄)이 사용될 수 있다.
온도 계산에 대한 일반적인 예는 다음과 같이 계산되는 소위 “빠른 시뮬레이션 annealing“입니다.
- 온도 = initial_temperature / (iteration_number + 1)
반복 번호가 0에서 시작하는 경우 반복 번호에 1을 추가하여 0으로 나누기 오류를 방지합니다.
더 나쁜 솔루션의 수용은 온도뿐만 아니라 더 나쁜 솔루션의 목적 함수 평가와 현재 솔루션 간의 차이를 사용합니다. 이 정보를 사용하여 0과 1 사이의 값이 계산되어 더 나쁜 솔루션을 받아들일 가능성을 나타냅니다. 그런 다음 이 분포는 난수를 사용하여 샘플링되며, 값보다 작으면 더 나쁜 솔루션이 허용됨을 의미합니다.
메트로폴리스 기준으로 알려진 이 수용 확률은 온도가 높을 때 알고리즘이 국소 최소값에서 벗어날 수 있도록 합니다.
— 128페이지, 최적화 알고리즘, 2019.
이를 metropolis acceptance criterion이라고하며 최소화는 다음과 같이 계산됩니다.
- 기준 = exp( -(대물(신규) – 대물(현재)) / 온도)
여기서 exp()는 제공된 인수의 거듭제곱으로 상승한 e(수학 상수)이고, objective(new) 및 objective(current)는 새로운(더 나쁜) 및 현재 후보 솔루션의 객관적 함수 평가입니다.
그 결과 열악한 솔루션은 검색 초기에 수락될 가능성이 더 높고 검색 후반에 수락될 가능성이 적습니다. 의도는 검색 초기의 고온이 검색이 글로벌 최적 값을 찾는 데 도움이되고 검색 후반의 낮은 온도는 알고리즘이 글로벌 최적 값을 연마하는 데 도움이된다는 것입니다.
온도가 높게 시작되어 프로세스가 검색 공간을 자유롭게 이동할 수 있으며,이 단계에서 프로세스가 최상의 로컬 최소값을 가진 좋은 지역을 찾을 수 있기를 바랍니다. 그런 다음 온도를 천천히 낮추어 확률을 줄이고 검색을 최소한으로 수렴합니다.
— 128페이지, 최적화 알고리즘, 2019.
이제 Simulated annealing 알고리즘에 익숙해졌으므로 처음부터 구현하는 방법을 살펴보겠습니다.
Simulated annealing 구현
이 섹션에서는 Simulated annealing 최적화 알고리즘을 처음부터 구현하는 방법을 살펴보겠습니다.
먼저 목적 함수와 각 입력 변수의 한계를 목적 함수로 정의해야 합니다. 목적 함수는 objective() 라는 이름을 지정할 파이썬 함수입니다. 범위는 변수의 최소값과 최대값을 정의하는 각 입력 변수에 대해 하나의 차원이 있는 2D 배열입니다.
예를 들어, 1차원 목적 함수와 범위는 다음과 같이 정의됩니다.
| # objective function def objective(x): return 0 # define range for input bounds = asarray([[–5.0, 5.0]]) |
다음으로, 초기 점을 문제 범위 내의 임의의 점으로 생성 한 다음 목적 함수를 사용하여 평가할 수 있습니다.
| ... # generate an initial point best = bounds[:, 0] + rand(len(bounds)) * (bounds[:, 1] – bounds[:, 0]) # evaluate the initial point best_eval = objective(best) |
검색의 초점이며 더 나은 솔루션으로 대체 될 수있는 “현재“솔루션을 유지해야합니다.
| ... # current working solution curr, curr_eval = best, best_eval |
이제 “n_iterations“로 정의된 알고리즘의 미리 정의된 반복 횟수(예: 100 또는 1,000)를 반복할 수 있습니다.
| ... # run the algorithm for i in range(n_iterations): ... |
알고리즘 반복의 첫 번째 단계는 현재 작업 솔루션에서 새 후보 솔루션을 생성하는 것입니다(예: 단계 수행).
이를 위해서는 검색 공간의 경계에 상대적인 미리 정의된 “step_size” 매개 변수가 필요합니다. 평균이 현재 지점이고 표준 편차가 “step_size“로 정의되는 가우스 분포로 무작위 단계를 수행합니다. 즉, 수행 된 단계의 약 99 %가 현재 지점에서 3 * step_size 이내가됩니다.
| ... # take a step candidate = solution + randn(len(bounds)) * step_size |
우리는 이런 식으로 조치를 취할 필요가 없습니다. 0과 단계 크기 사이의 균일 분포를 사용할 수 있습니다. 예를 들어:
| ... # take a step candidate = solution + rand(len(bounds)) * step_size |
다음으로 평가해야합니다.
| ... # evaluate candidate point candidate_eval = objective(candidate) |
그런 다음 이 새로운 포인트에 대한 평가가 현재 최고 포인트와 같거나 더 나은지 확인하고, 그렇다면 현재 최고 포인트를 이 새 포인트로 바꿔야 합니다.
이것은 검색의 초점인 현재 작업 솔루션과는 별개입니다.
| ... # check for new best solution if candidate_eval < best_eval: # store new best point best, best_eval = candidate, candidate_eval # report progress print(‘>%d f(%s) = %.5f’ % (i, best, best_eval)) |
다음으로 현재 작동하는 솔루션을 교체 할 준비를해야합니다.
첫 번째 단계는 현재 솔루션의 목적 함수 평가와 현재 작업 솔루션의 차이를 계산하는 것입니다.
| ... # difference between candidate and current point evaluation diff = candidate_eval – curr_eval |
다음으로, 빠른 annealing 일정을 사용하여 현재 온도를 계산해야 하며, 여기서 “temp“는 인수로 제공된 초기 온도입니다.
| ... # calculate temperature for current epoch t = temp / float(i + 1) |
그런 다음 현재 작동하는 솔루션보다 성능이 더 나쁜 솔루션을 수락할 가능성을 계산할 수 있습니다.
| ... # calculate metropolis acceptance criterion metropolis = exp(–diff / t) |
마지막으로, 더 나은 목적 함수 평가 (차이가 음수) 또는 목적 함수가 더 나쁜 경우 새로운 점을 현재 작업 솔루션으로 받아 들일 수 있지만 확률 론적으로 받아들이기로 결정합니다.
| ... # check if we should keep the new point if diff < 0 or rand() < metropolis: # store the new current point curr, curr_eval = candidate, candidate_eval |
그리고 그게 전부입니다.
이 Simulated annealing 알고리즘을 목적 함수의 이름, 각 입력 변수의 한계, 총 반복, 스텝 크기 및 초기 온도를 인수로 사용하고 찾은 최상의 솔루션과 평가를 반환하는 재사용 가능한 함수로 구현할 수 있습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | # simulated annealing algorithm
def simulated_annealing(objective, bounds, n_iterations, step_size, temp):
# generate an initial point
best = bounds[:, 0] + rand(len(bounds)) * (bounds[:, 1] – bounds[:, 0])
# evaluate the initial point
best_eval = objective(best)
# current working solution
curr, curr_eval = best, best_eval
# run the algorithm
for i in range(n_iterations):
# take a step
candidate = curr + randn(len(bounds)) * step_size
# evaluate candidate point
candidate_eval = objective(candidate)
# check for new best solution
if candidate_eval < best_eval:
# store new best point
best, best_eval = candidate, candidate_eval
# report progress
print(‘>%d f(%s) = %.5f’ % (i, best, best_eval))
# difference between candidate and current point evaluation
diff = candidate_eval – curr_eval
# calculate temperature for current epoch
t = temp / float(i + 1)
# calculate metropolis acceptance criterion
metropolis = exp(-diff / t)
# check if we should keep the new point
if diff < 0 or rand() < metropolis:
# store the new current point
curr, curr_eval = candidate, candidate_eval
return [best, best_eval]
|
이제 Python에서 Simulated annealing 알고리즘을 구현하는 방법을 알았으므로 이를 사용하여 목적 함수를 최적화하는 방법을 살펴보겠습니다.
Simulated annealing 작업 예제
이 섹션에서는 Simulated annealing 최적화 알고리즘을 목적 함수에 적용합니다.
먼저 목적 함수를 정의해 보겠습니다.
경계 [-5, 5]가 있는 간단한 1차원 x^2 목적 함수를 사용합니다.
아래 예제에서는 함수를 정의한 다음 입력값 그리드에 대한 함수의 응답 표면의 선 플롯을 만들고 f(0.0) = 0.0에서 최적값을 빨간색 선으로 표시합니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | # convex unimodal optimization function from numpy import arange from matplotlib import pyplot # objective function def objective(x): return x[0]**2.0 # define range for input r_min, r_max = –5.0, 5.0 # sample input range uniformly at 0.1 increments inputs = arange(r_min, r_max, 0.1) # compute targets results = [objective([x]) for x in inputs] # create a line plot of input vs result pyplot.plot(inputs, results) # define optimal input value x_optima = 0.0 # draw a vertical line at the optimal input pyplot.axvline(x=x_optima, ls=‘–‘, color=‘red’) # show the plot pyplot.show() |
예제를 실행하면 목적 함수의 선 그림이 생성되고 함수 optima가 명확하게 표시됩니다.
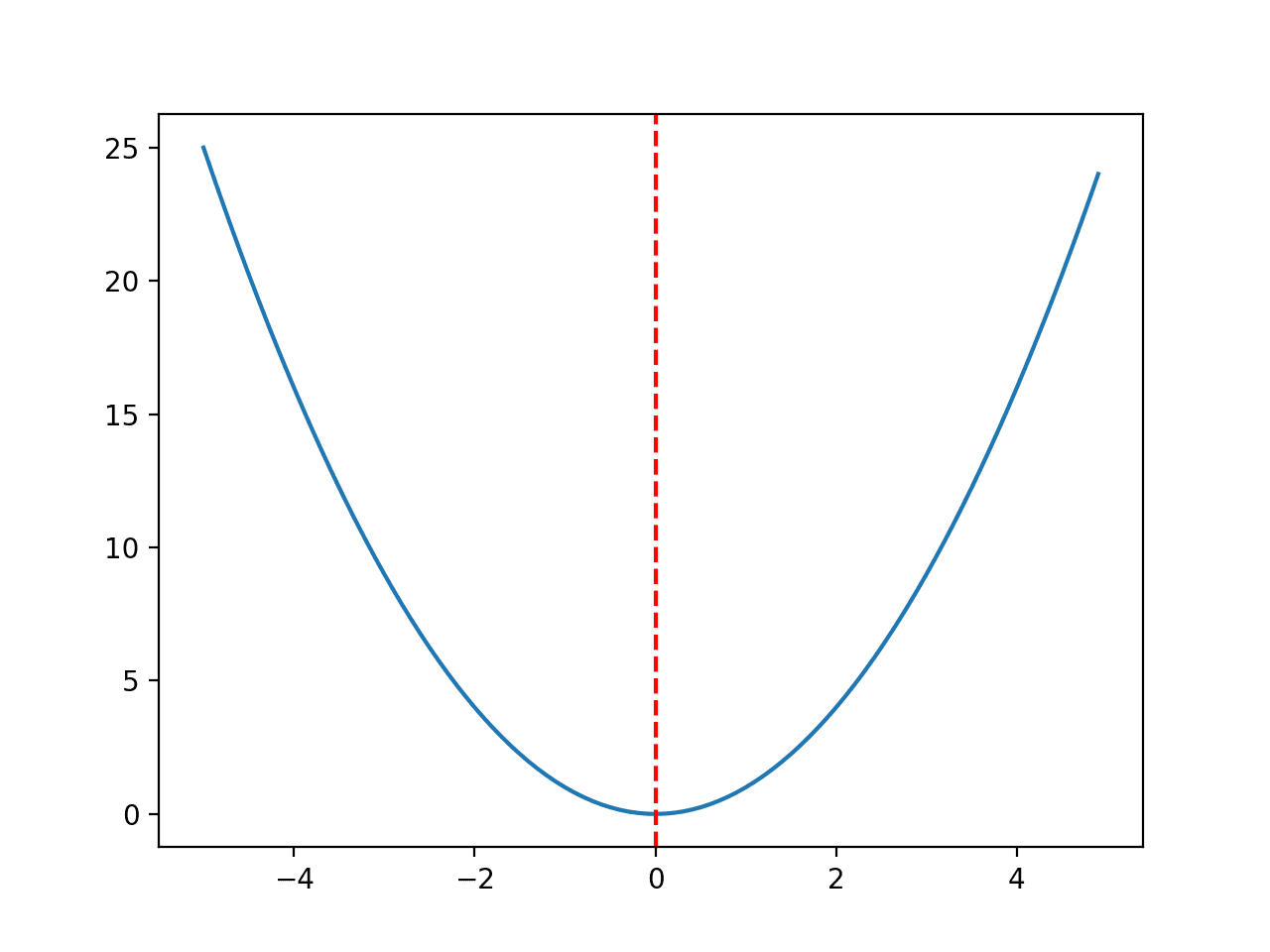
최적값이 빨간색 파선으로 표시된 목적 함수의 선 플롯
최적화 알고리즘을 문제에 적용하기 전에 잠시 시간을 내어 수용 기준을 좀 더 잘 이해해 보겠습니다.
첫째, 빠른 annealing 일정은 반복 횟수의 지수 함수입니다. 각 알고리즘 반복에 대한 온도 플롯을 만들어이를 명확히 할 수 있습니다.
우리는 임의로 선택된 10 및 100 알고리즘 반복의 초기 온도를 사용합니다.
전체 예제는 다음과 같습니다.
| # explore temperature vs algorithm iteration for simulated annealing from matplotlib import pyplot # total iterations of algorithm iterations = 100 # initial temperature initial_temp = 10 # array of iterations from 0 to iterations – 1 iterations = [i for i in range(iterations)] # temperatures for each iterations temperatures = [initial_temp/float(i + 1) for i in iterations] # plot iterations vs temperatures pyplot.plot(iterations, temperatures) pyplot.xlabel(‘Iteration’) pyplot.ylabel(‘Temperature’) pyplot.show() |
예제를 실행하면 각 알고리즘 반복의 온도가 계산되고 알고리즘 반복(x축) 대 온도(y축)의 플롯이 생성됩니다.
온도가 선형이 아닌 기하 급수적으로 빠르게 떨어지므로 20 회 반복 후 1 미만이되고 나머지 검색 동안 낮게 유지되는 것을 볼 수 있습니다.
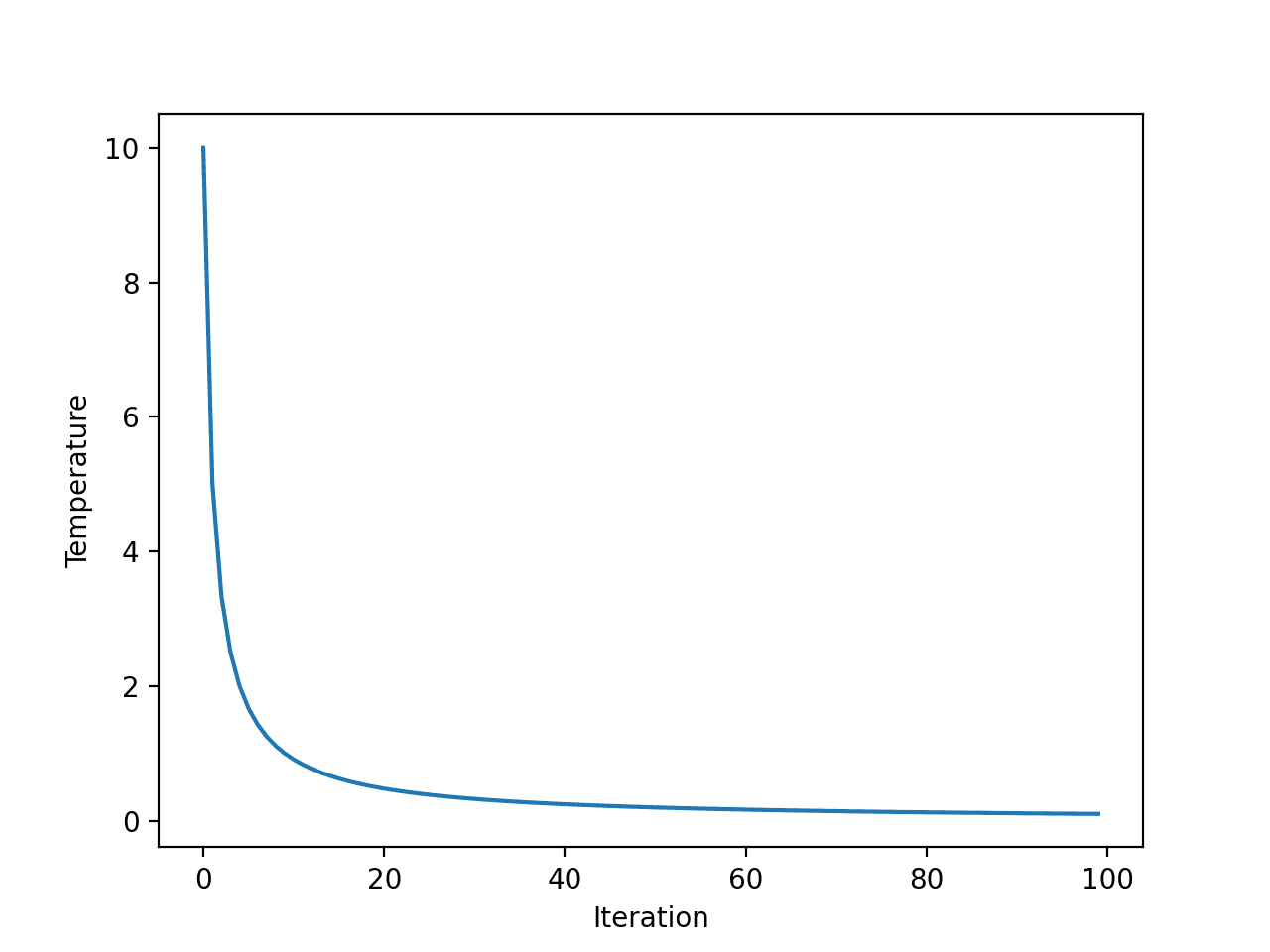
빠른 annealing을 위한 온도 대 알고리즘 반복의 선 플롯
다음으로, metropolis acceptance criterion이 온도에 따라 시간이 지남에 따라 어떻게 변하는 지 더 잘 알 수 있습니다.
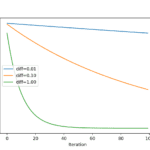
기준은 온도의 함수이지만 새로운 포인트의 객관적인 평가가 현재 작업 솔루션과 얼마나 다른지에 대한 함수이기도합니다. 따라서 몇 가지 다른 “목적 함수 값의 차이“에 대한 기준을 플롯하여 합격 확률에 미치는 영향을 확인합니다.
전체 예제는 다음과 같습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | # explore metropolis acceptance criterion for simulated annealing from math import exp from matplotlib import pyplot # total iterations of algorithm iterations = 100 # initial temperature initial_temp = 10 # array of iterations from 0 to iterations – 1 iterations = [i for i in range(iterations)] # temperatures for each iterations temperatures = [initial_temp/float(i + 1) for i in iterations] # metropolis acceptance criterion differences = [0.01, 0.1, 1.0] for d in differences: metropolis = [exp(–d/t) for t in temperatures] # plot iterations vs metropolis label = ‘diff=%.2f’ % d pyplot.plot(iterations, metropolis, label=label) # inalize plot pyplot.xlabel(‘Iteration’) pyplot.ylabel(‘Metropolis Criterion’) pyplot.legend() pyplot.show() |
예제를 실행하면 각 반복에 대해 표시된 온도를 사용하여 각 알고리즘 반복에 대한 대도시 허용 기준이 계산됩니다(이전 섹션 참조).
플롯에는 새로운 더 나쁜 솔루션과 현재 작업 솔루션 간의 세 가지 차이점에 대한 세 개의 선이 있습니다.
솔루션이 나쁠수록(차이가 클수록) 예상대로 알고리즘 반복에 관계없이 모델이 더 나쁜 솔루션을 받아들일 가능성이 적다는 것을 알 수 있습니다. 또한 모든 경우에 알고리즘 반복에 따라 더 나쁜 솔루션을 수용 할 가능성이 감소한다는 것을 알 수 있습니다.
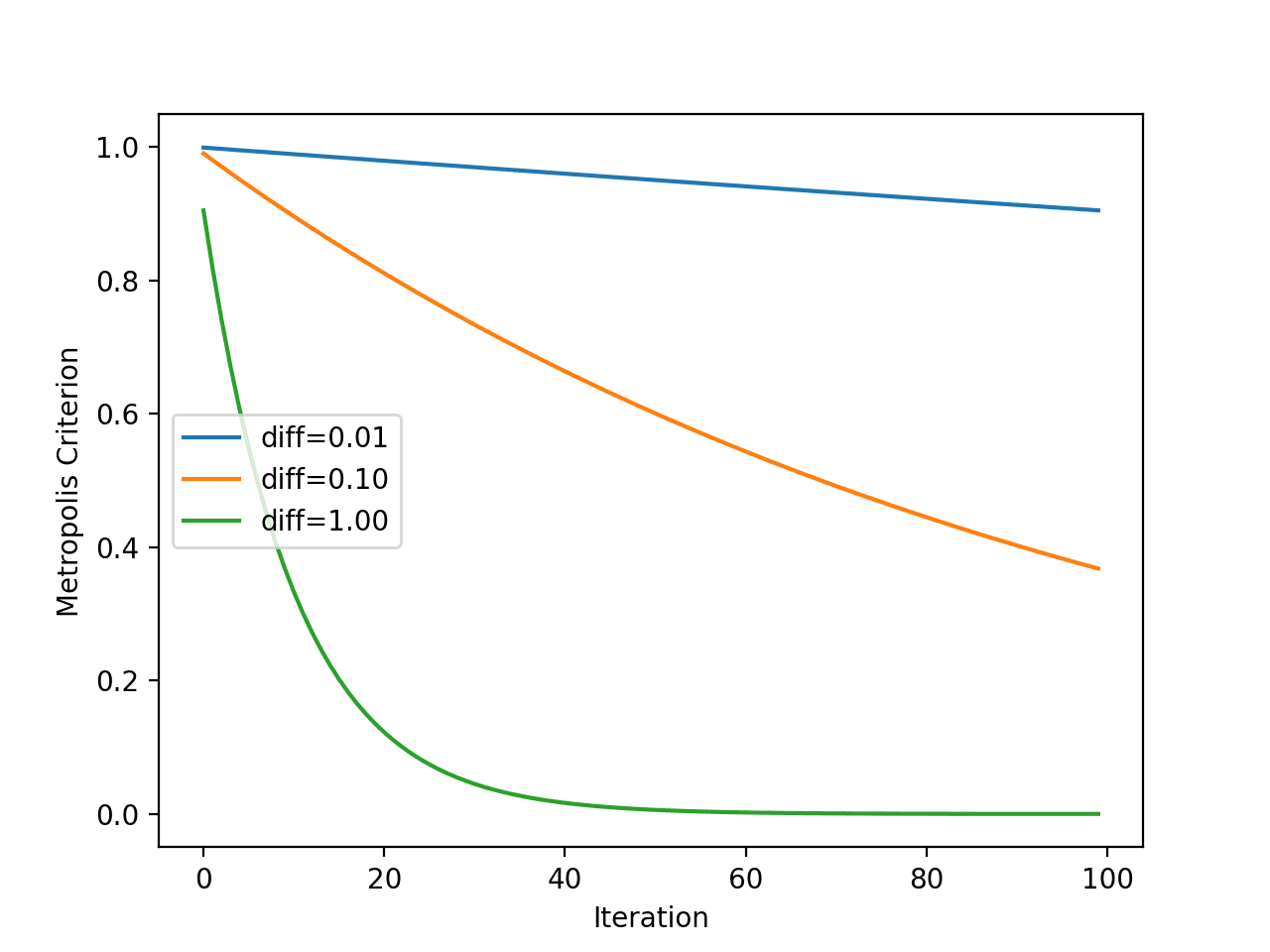
metropolis acceptance criterion의 선 플롯 vs. Simulated annealing을 위한 알고리즘 반복
이제 시간 경과에 따른 온도 및 metropolis acceptance criterion의 동작에 더 익숙해졌으므로 시뮬레이션 annealing을 테스트 문제에 적용해 보겠습니다.
먼저 의사 난수 생성기를 시드합니다.
이것은 일반적으로 필요하지 않지만이 경우 알고리즘을 실행할 때마다 동일한 결과 (동일한 난수 시퀀스)를 얻도록하여 나중에 결과를 플롯 할 수 있도록하고 싶습니다.
| ... # seed the pseudorandom number generator seed(1) |
다음으로 검색 구성을 정의할 수 있습니다.
이 경우 알고리즘을 1,000회 반복하고 단계 크기 0.1을 사용합니다. 단계를 생성하기 위해 가우스 함수를 사용하고 있다고 가정하면 이는 취해진 모든 단계의 약 99%가 주어진 지점의 (0.1 * 3) 거리 내에 있음을 의미합니다(예: 3개의 표준 편차).
또한 초기 온도 10.0을 사용합니다. 검색 절차는 초기 온도보다 annealing 일정에 더 민감하므로 초기 온도 값은 거의 임의적입니다.
| ... n_iterations = 1000 # define the maximum step size step_size = 0.1 # initial temperature temp = 10 |
다음으로 검색을 수행하고 결과를보고 할 수 있습니다.
| ... # perform the simulated annealing search best, score = simulated_annealing(objective, bounds, n_iterations, step_size, temp) print(‘Done!’) print(‘f(%s) = %f’ % (best, score)) |
이 모든 것을 함께 묶어 전체 예제가 아래에 나열되어 있습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 | # simulated annealing search of a one-dimensional objective function
from numpy import asarray
from numpy import exp
from numpy.random import randn
from numpy.random import rand
from numpy.random import seed
# objective function
def objective(x):
return x[0]**2.0
# simulated annealing algorithm
def simulated_annealing(objective, bounds, n_iterations, step_size, temp):
# generate an initial point
best = bounds[:, 0] + rand(len(bounds)) * (bounds[:, 1] – bounds[:, 0])
# evaluate the initial point
best_eval = objective(best)
# current working solution
curr, curr_eval = best, best_eval
# run the algorithm
for i in range(n_iterations):
# take a step
candidate = curr + randn(len(bounds)) * step_size
# evaluate candidate point
candidate_eval = objective(candidate)
# check for new best solution
if candidate_eval < best_eval:
# store new best point
best, best_eval = candidate, candidate_eval
# report progress
print(‘>%d f(%s) = %.5f’ % (i, best, best_eval))
# difference between candidate and current point evaluation
diff = candidate_eval – curr_eval
# calculate temperature for current epoch
t = temp / float(i + 1)
# calculate metropolis acceptance criterion
metropolis = exp(-diff / t)
# check if we should keep the new point
if diff < 0 or rand() < metropolis:
# store the new current point
curr, curr_eval = candidate, candidate_eval
return [best, best_eval]
# seed the pseudorandom number generator
seed(1)
# define range for input
bounds = asarray([[-5.0, 5.0]])
# define the total iterations
n_iterations = 1000
# define the maximum step size
step_size = 0.1
# initial temperature
temp = 10
# perform the simulated annealing search
best, score = simulated_annealing(objective, bounds, n_iterations, step_size, temp)
print(‘Done!’)
print(‘f(%s) = %f’ % (best, score))
|
예제를 실행하면 반복 횟수, 함수에 대한 입력값, 개선이 감지될 때마다 목적 함수의 응답 변수를 포함한 검색 진행률이 보고됩니다.
검색이 끝나면 최상의 솔루션이 발견되고 평가가보고됩니다.
참고: 결과는 알고리즘 또는 평가 절차의 확률적 특성 또는 수치 정밀도의 차이에 따라 달라질 수 있습니다. 예제를 몇 번 실행하고 평균 결과를 비교하는 것이 좋습니다.
이 경우 알고리즘의 1,000회 반복에 비해 약 20개의 개선 사항과 f(0.0) = 0.0으로 평가되는 최적 입력 0.0에 매우 가까운 솔루션을 볼 수 있습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | >34 f([-0.78753544]) = 0.62021 >35 f([-0.76914239]) = 0.59158 >37 f([-0.68574854]) = 0.47025 >39 f([-0.64797564]) = 0.41987 >40 f([-0.58914623]) = 0.34709 >41 f([-0.55446029]) = 0.30743 >42 f([-0.41775702]) = 0.17452 >43 f([-0.35038542]) = 0.12277 >50 f([-0.15799045]) = 0.02496 >66 f([-0.11089772]) = 0.01230 >67 f([-0.09238208]) = 0.00853 >72 f([-0.09145261]) = 0.00836 >75 f([-0.05129162]) = 0.00263 >93 f([-0.02854417]) = 0.00081 >144 f([0.00864136]) = 0.00007 >149 f([0.00753953]) = 0.00006 >167 f([-0.00640394]) = 0.00004 >225 f([-0.00044965]) = 0.00000 >503 f([-0.00036261]) = 0.00000 >512 f([0.00013605]) = 0.00000 Done! f([0.00013605]) = 0.000000 |
개선이있을 때마다 최상의 솔루션 평가의 변화를 보여주는 선 그림으로 검색 진행률을 검토하는 것은 흥미로울 수 있습니다.
개선이있을 때마다 목적 함수 평가를 추적하고이 점수 목록을 반환하도록 simulated_annealing ()를 업데이트 할 수 있습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | # simulated annealing algorithm
def simulated_annealing(objective, bounds, n_iterations, step_size, temp):
# generate an initial point
best = bounds[:, 0] + rand(len(bounds)) * (bounds[:, 1] – bounds[:, 0])
# evaluate the initial point
best_eval = objective(best)
# current working solution
curr, curr_eval = best, best_eval
# run the algorithm
for i in range(n_iterations):
# take a step
candidate = curr + randn(len(bounds)) * step_size
# evaluate candidate point
candidate_eval = objective(candidate)
# check for new best solution
if candidate_eval < best_eval:
# store new best point
best, best_eval = candidate, candidate_eval
# keep track of scores
scores.append(best_eval)
# report progress
print(‘>%d f(%s) = %.5f’ % (i, best, best_eval))
# difference between candidate and current point evaluation
diff = candidate_eval – curr_eval
# calculate temperature for current epoch
t = temp / float(i + 1)
# calculate metropolis acceptance criterion
metropolis = exp(-diff / t)
# check if we should keep the new point
if diff < 0 or rand() < metropolis:
# store the new current point
curr, curr_eval = candidate, candidate_eval
return [best, best_eval, scores]
|
그런 다음 이러한 점수의 선 그림을 만들어 검색 중에 발견된 각 개선에 대한 목적 함수의 상대적 변화를 확인할 수 있습니다.
| ... # line plot of best scores pyplot.plot(scores, ‘.-‘) pyplot.xlabel(‘Improvement Number’) pyplot.ylabel(‘Evaluation f(x)’) pyplot.show() |
이를 함께 묶어 검색을 수행하고 검색 중에 향상된 솔루션의 목적 함수 점수를 플로팅하는 전체 예가 아래에 나열되어 있습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 | # simulated annealing search of a one-dimensional objective function
from numpy import asarray
from numpy import exp
from numpy.random import randn
from numpy.random import rand
from numpy.random import seed
from matplotlib import pyplot
# objective function
def objective(x):
return x[0]**2.0
# simulated annealing algorithm
def simulated_annealing(objective, bounds, n_iterations, step_size, temp):
# generate an initial point
best = bounds[:, 0] + rand(len(bounds)) * (bounds[:, 1] – bounds[:, 0])
# evaluate the initial point
best_eval = objective(best)
# current working solution
curr, curr_eval = best, best_eval
scores = list()
# run the algorithm
for i in range(n_iterations):
# take a step
candidate = curr + randn(len(bounds)) * step_size
# evaluate candidate point
candidate_eval = objective(candidate)
# check for new best solution
if candidate_eval < best_eval:
# store new best point
best, best_eval = candidate, candidate_eval
# keep track of scores
scores.append(best_eval)
# report progress
print(‘>%d f(%s) = %.5f’ % (i, best, best_eval))
# difference between candidate and current point evaluation
diff = candidate_eval – curr_eval
# calculate temperature for current epoch
t = temp / float(i + 1)
# calculate metropolis acceptance criterion
metropolis = exp(-diff / t)
# check if we should keep the new point
if diff < 0 or rand() < metropolis:
# store the new current point
curr, curr_eval = candidate, candidate_eval
return [best, best_eval, scores]
# seed the pseudorandom number generator
seed(1)
# define range for input
bounds = asarray([[-5.0, 5.0]])
# define the total iterations
n_iterations = 1000
# define the maximum step size
step_size = 0.1
# initial temperature
temp = 10
# perform the simulated annealing search
best, score, scores = simulated_annealing(objective, bounds, n_iterations, step_size, temp)
print(‘Done!’)
print(‘f(%s) = %f’ % (best, score))
# line plot of best scores
pyplot.plot(scores, ‘.-‘)
pyplot.xlabel(‘Improvement Number’)
pyplot.ylabel(‘Evaluation f(x)’)
pyplot.show()
|
예제를 실행하면 이전과 같이 검색이 수행되고 결과가 보고됩니다.
언덕 오르기 검색 중 각 개선에 대한 목적 함수 평가를 보여주는 선 그림이 생성됩니다. 검색 중에 목적 함수 평가에 대한 약 20개의 변경 사항을 볼 수 있으며, 알고리즘이 최적에 수렴함에 따라 처음에는 큰 변화가 있고 검색이 끝날 무렵에는 매우 작거나 감지할 수 없는 변화가 있습니다.
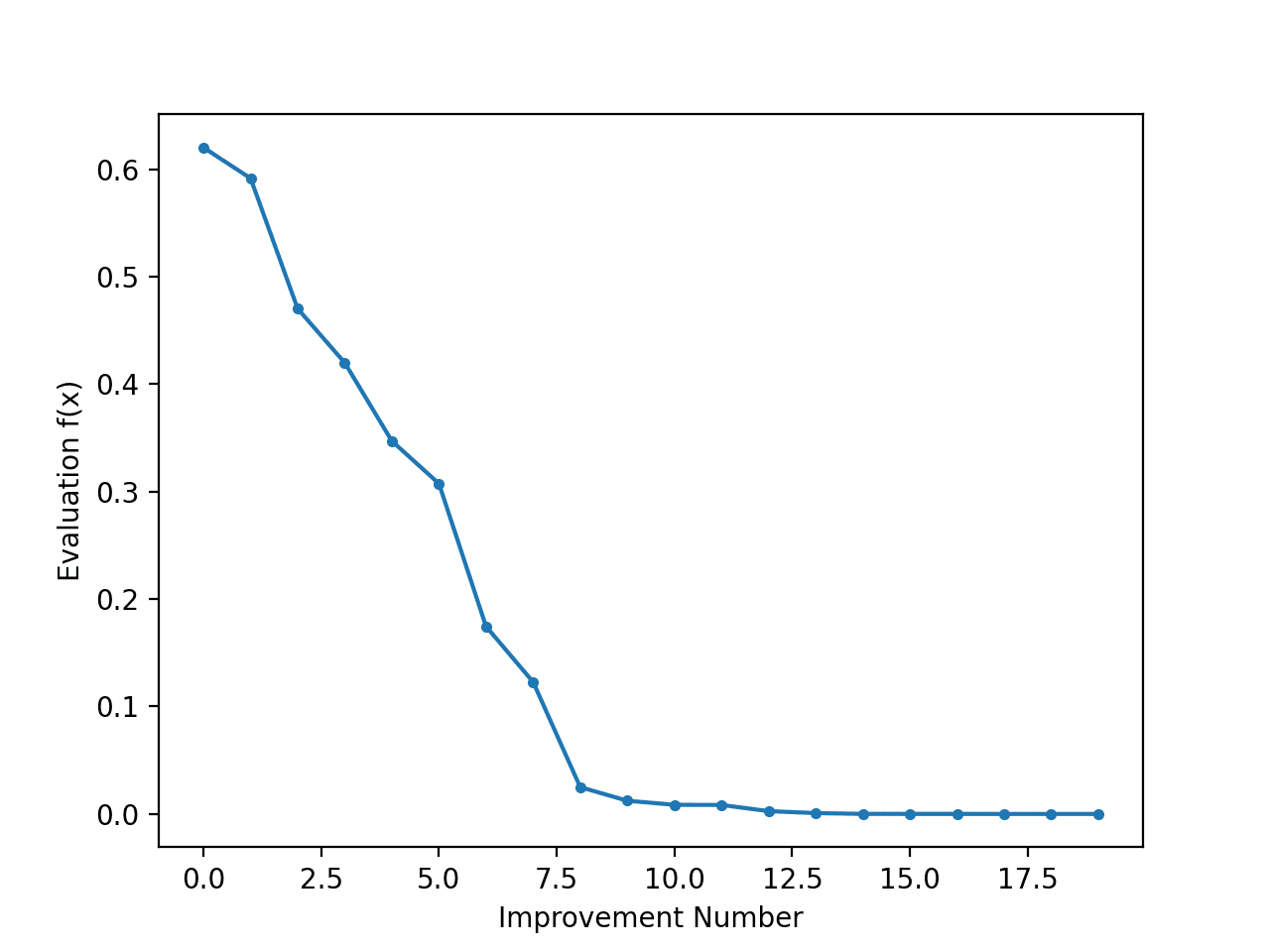
Simulated annealing 검색 중 각 개선에 대한 목적 함수 평가의 선 그림
추가 정보
이 섹션에서는 더 자세히 알아보려는 경우 주제에 대한 더 많은 리소스를 제공합니다.
논문
책
기사
요약
이 자습서에서는 함수 최적화를 위한 Simulated annealing 최적화 알고리즘을 발견했습니다.
특히 다음 내용을 배웠습니다.
- Simulated annealing은 함수 최적화를 위한 확률적 전역 검색 알고리즘입니다.
- Python에서 시뮬레이션 된 annealing 알고리즘을 처음부터 구현하는 방법.
- Simulated annealing 알고리즘을 사용하고 알고리즘의 결과를 검사하는 방법