





RTX 4090 머신러닝 성능 테스트
Intro
4세대 텐서코어를 적용한 Nvidia사의 플래그십 GPU인 RTX 4090이 바로 지난주 출시되었습니다. 이 글은 RTX 4090 GPU와 RTX 3090 GPU를 하드웨어 스펙부터 머신러닝 성능까지 비교함으로써 RTX 4090 기반의 GPU 서버가 머신러닝의 성과를 얼마나 향상시킬 수 있는지 보여 드리고자 합니다. (테스트에는 NVIDIA CUDA 11.8 드라이버가 사용되었습니다.)
지금 바로 사용을 원하시는 분들께 조금이라도 더 빨리 제공해 드리고자 출시일 당일에 바로 제품을 구매하여 클라우드 서버를 구성해 놓았습니다. 사용 원하시거나 제품 관련 문의 있으시면 아래 연락처로 문의 주시기 바랍니다.
문의전화 : 010-2666-6871
이메일 : ikseon@nepirity.com
Test environment
NVIDIA NGC의 컨테이너화된 애플리케이션
- HPL 2.3 고성능 Linpack 태그: nvcr.io/nvidia/hpc-benchmarks:21.4-hpl
- HPCG 3.1 고성능 Conjugate Gradient solver 태그: nvcr.io/nvidia/hpc-benchmarks:21.4-hpcg3.1
- NAMD 3.0a11 분자 역학 태그: nvcr.io/hpc/namd:3.0-alpha11
- LAMMPS 분자 역학 태그: nvcr.io/hpc/lammps:patch_4May2022
- TensorFlow 1.15.5 ML/AI Framework 태그: nvcr.io/nvidia/tensorflow:22.09-tf1-py3
- PyTorch 1.13.0a0 ML/AI Framework 태그 : nvcr.io/nvidia/pytorch:22.09-py3
아래 차트는 RTX 4090의 우수한 컴퓨팅 성능을 RTX 3090과 비교하여 보여줍니다. 한가지 주의하실 점은, Ada Lovelace 아키텍처의 새로운 컴퓨팅 레벨 8.9에 완전히 최적화되지 않은 응용 프로그램을 사용한 결과이므로 향후 응용 프로그램의 최적화에 따라 성능은 더욱 향상될 수 있다는 것입니다.
테스트에 사용된 벤치마크 및 명령줄에 대한 몇 가지 세부 정보를 말씀 드릴 예정입니다. 참고로, 일부 결과값은 RTX 4090 작업 실행만 포함했지만 4090과 3090 모두 동일한 시스템에서 번갈아 가며 테스트되었음을 알려 드립니다.
HPL (Linpack)
Linpack은 NVIDIA GPU에서 실행되도록 만들어진 HPL Linpack 벤치 마크입니다. A100 및 H100과 같은 고급 컴퓨팅 GPU에서 테스트하기 위한 것이며, 다중 GPU 다중 노드 사용을 위한 설정입니다. Linpack은 Top500 슈퍼 컴퓨터의 순위를 매기는 데 사용되는 표준 벤치마크로서, 엄밀히 말하면 RTX GPU에서 실행하기 위한 것은 아닙니다. RTX GPU는 컴퓨팅 GPU에 비해 배정밀도(fp64) 성능이 매우 떨어집니다. 그러나 단정밀도(fp32) 성능은 상대적으로 매우 우수합니다. HPL-AI라는 벤치 마크의 fp32 버전이 있지만 아쉽게도 본 테스트에 사용할 수는 없었습니다.
대신 fp64 HPL 결과를 포함하기로 결정한 이유는 A100보다 거의 10배 낮은 성능이지만 16-24 코어 CPU에 비해 여전히 준수하기 때문입니다. A100 또는 H100용 코드로 작업하는 개발자는 코드를 A100 또는 H100으로 이동하기 전에 RTX 4090에서 개발하고 테스트 할 수 있겠습니다.
명령줄:
CUDA_VISIBLE_DEVICES=0 mpirun --mca btl smcuda,self -x UCX_TLS=sm,cuda,cuda_copy,cuda_ipc -np 1 hpl.sh --dat ./HPL.dat --cpu-affinity 0 --cpu-cores-per-rank 4 --gpu-affinity 0
4090 출력 :
2022-10-10 19:58:13.576 ================================================================================ T/V N NB P Q Time Gflops -------------------------------------------------------------------------------- WR03L2L2 48000 288 1 1 62.41 1.183e+03 -------------------------------------------------------------------------------- ||Ax-b||_oo/(eps*(||A||_oo*||x||_oo+||b||_oo)*N)= 0.0045393 ...... PASSED ================================================================================
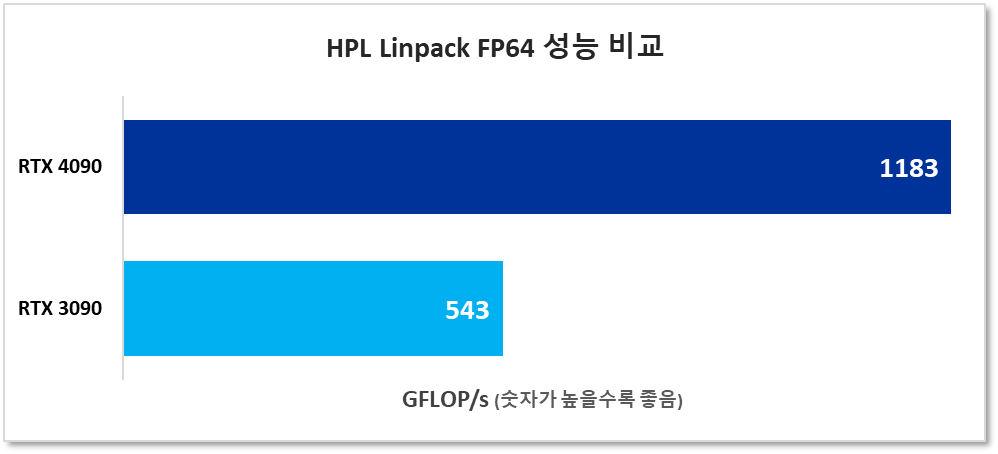
노트:
- 이 벤치마크는 RTX GPU에서 크게 감소되는 배정밀도 부동 소수점 기능을 많이 사용합니다.
- 지포스 GPU가 테라 플롭 이상의 fp64 성능을 보여준다는 점이 놀랍습니다.
HPCG
HPCG(High Performance Conjugate Gradient)는 메모리 바인딩 애플리케이션으로서 Top500 슈퍼 컴퓨터를 선별할 때 사용된 벤치마크 중 하나입니다. 이 벤치마크에 대한 GPU 결과는 일반적으로 GPU에 장착된 고성능 메모리로 인해 하이엔드 CPU보다 훨씬 높습니다.
명령줄:
mpirun --mca btl smcuda,self -x UCX_TLS=sm,cuda,cuda_copy,cuda_ipc -np 1 hpcg.sh --dat ./hpcg.dat --cpu-affinity 0 --cpu-cores-per-rank 4 --gpu-affinity 0
4090 출력 :
SpMV = 145.6 GF ( 917.2 GB/s Effective) 145.6 GF_per ( 917.2 GB/s Effective) SymGS = 181.1 GF (1397.8 GB/s Effective) 181.1 GF_per (1397.8 GB/s Effective) total = 171.4 GF (1299.6 GB/s Effective) 171.4 GF_per (1299.6 GB/s Effective) final = 162.2 GF (1230.1 GB/s Effective) 162.2 GF_per (1230.1 GB/s Effective)

노트 :
- HPCG 결과는 메모리 성능이 둘 다 유사하기 때문에 4090 및 3090에서 거의 동일할 것으로 예상됩니다.
NAMD
분자 역학 패키지 NAMD 3.0 알파 11의 GPU 상주 버전으로 테스트해 보았습니다.
명령줄:
echo "CUDASOAintegrate on" >> v3-stmv.namd namd3 +p1 +setcpuaffinity +idlepoll +devices 0 v3-stmv.namd
4090 STMV 출력:
Info: Benchmark time: 1 CPUs 0.0104954 s/step 8.23218 ns/day 0 MB memory TIMING: 500 CPU: 6.17736, 0.0105293/step Wall: 6.18515, 0.0104489/step, 8.2688 ns/days, 0 hours remaining, 0.000000 MB of memory in use. ENERGY: 500 357236.6193 279300.1236 81947.6998 5091.0071 -4504684.2417 381649.5571 0.0000 0.0000 947494.7573 -2451964.4774 298.0115 -3399459.2347 -2443255.3272 297.9991 1256.7666 33.2244 10200288.8725 -42.3066 -11.3685
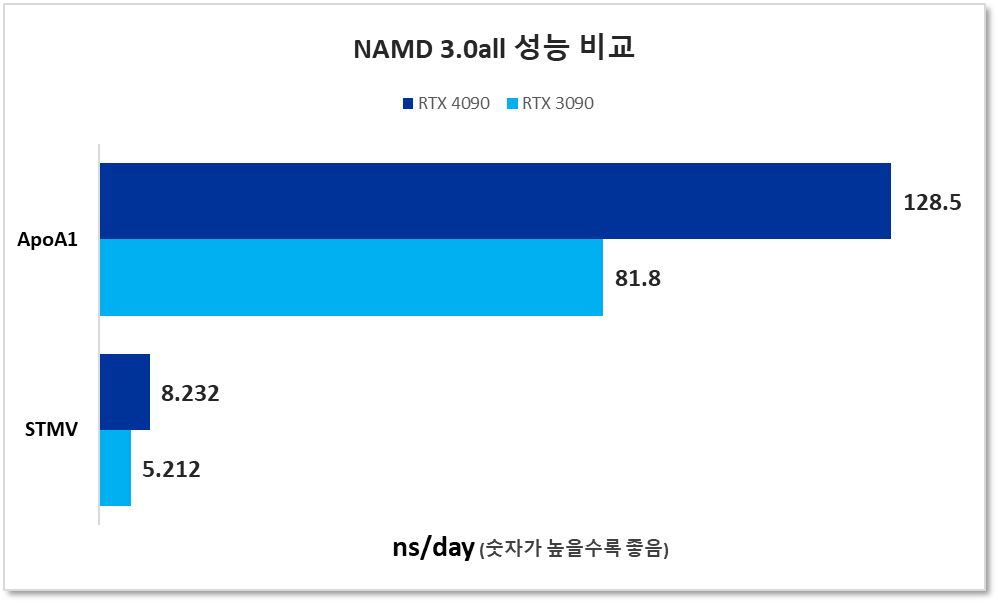
노트 :
- 대부분의 분자 역학 응용 프로그램과 마찬가지로 NAMD는 GPU 가속이 뛰어납니다. 이 GPU 상주 버전은 CPU-GPU 버전에 비해 크게 개선되었습니다.
- “CUDASOAintegrate on”을 NAMD 3의 작업 입력 파일에 추가해야 합니다.
LAMMPS
명령줄:
mpirun -n 1 lmp -k on g 1 -sf kk -pk kokkos cuda/aware on neigh full comm device binsize 2.8 -var x 8 -var y 8 -var z 8 -in in.lj
4090lj 출력:
Loop time of 5.94622 on 1 procs for 100 steps with 16384000 atoms Performance: 7265.125 tau/day, 16.817 timesteps/s 100.0% CPU use with 1 MPI tasks x 1 OpenMP threads
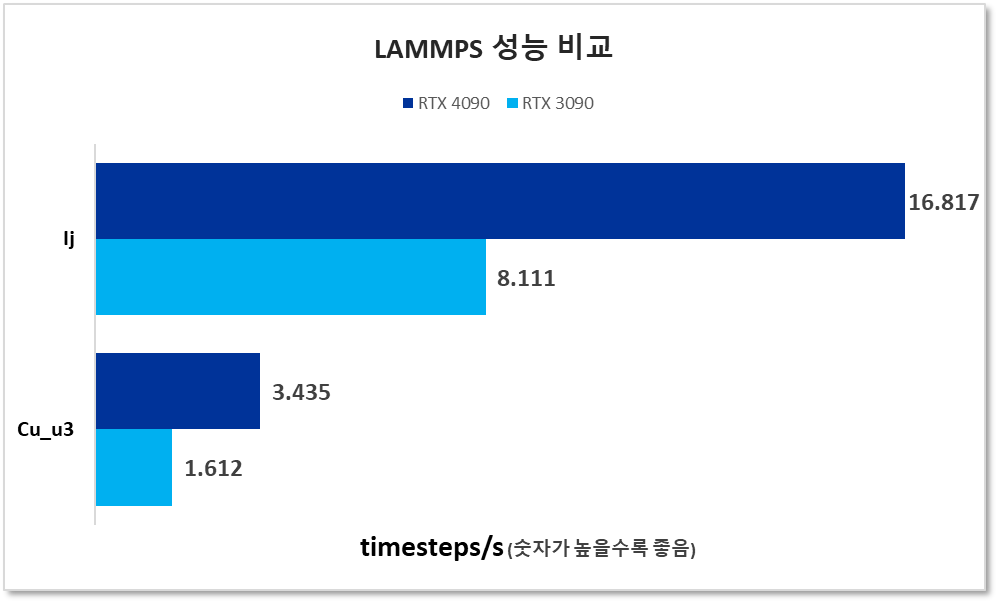
노트:
- LAMMPS는 Los Alamos National Lab에서 개발된 분자 역학 응용 프로그램입니다.
- LAMMPS에는 많은 빌드 옵션이 있습니다. 테스트에는 NGC의 NVIDIA 최적화 컨테이너가 사용되었습니다.
- LAMMPS 성능은 3090에 비해 4090에서 두 배로 증가했습니다.
Cu_u3: 벌크 Cu 격자 16384000 atoms
lj: 3d 레나드-존스 용융 55296000 atoms
https://download.lammps.org/tars/lammps-10Mar2021.tar.gz
TensorFlow 1.15.5 ResNet50
이 버전은 NVIDIA가 유지 관리하는 버전 1로서 일반적으로 버전 2보다 약간 나은 성능을 제공합니다. 벤치마크는 ResNet 50 계층 컨볼루션 신경망(CNN)을 50 단계 학습시키는 것입니다. 실행 단계에서 초당 가장 높은 이미지 값이 결과입니다. FP32 및 FP16(텐서코어) 작업이 실행되었습니다.
명령줄:
CUDA_VISIBLE_DEVICES=0 python resnet.py --layers=50 --batch_size=128 --precision=fp16
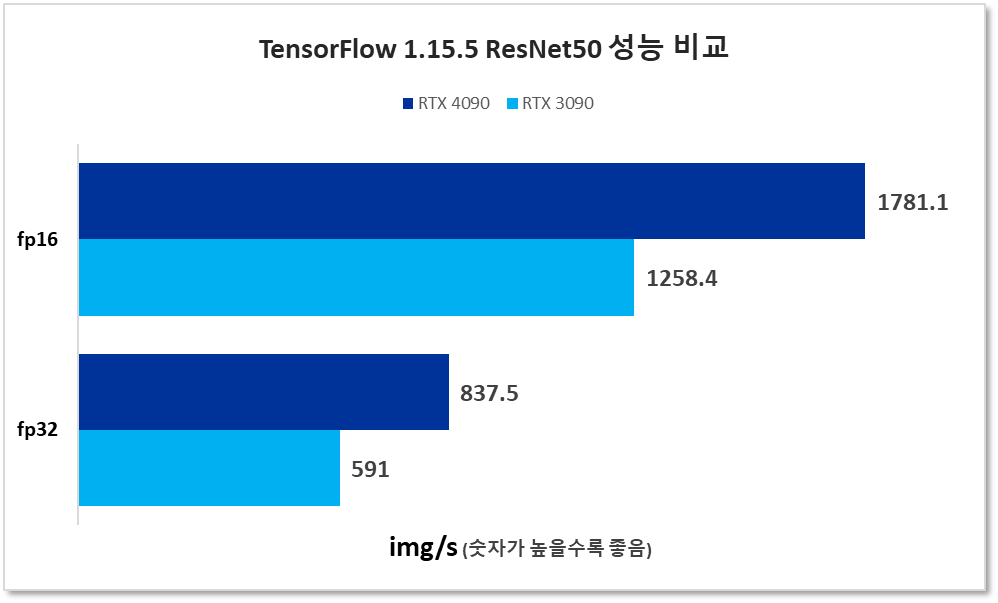
노트:
- XLA는 과거에 수행한 벤치마크 실행과의 일관성을 위해 작업 실행에 사용되지 않았습니다. 향후에는 벤치마킹에 포함할 계획입니다.
PyTorch 1.13 Transformer 학습
이 벤치마크는 CUDA가 있는 Wikitext-2에서 Transformer 모델의 6 epoch 학습에 PyTorch 1.13을 사용했습니다.
명령줄:
time CUDA_VISIBLE_DEVICES=0 python main.py --cuda --epochs 6 --model Transformer --lr 5 --batch_size 640
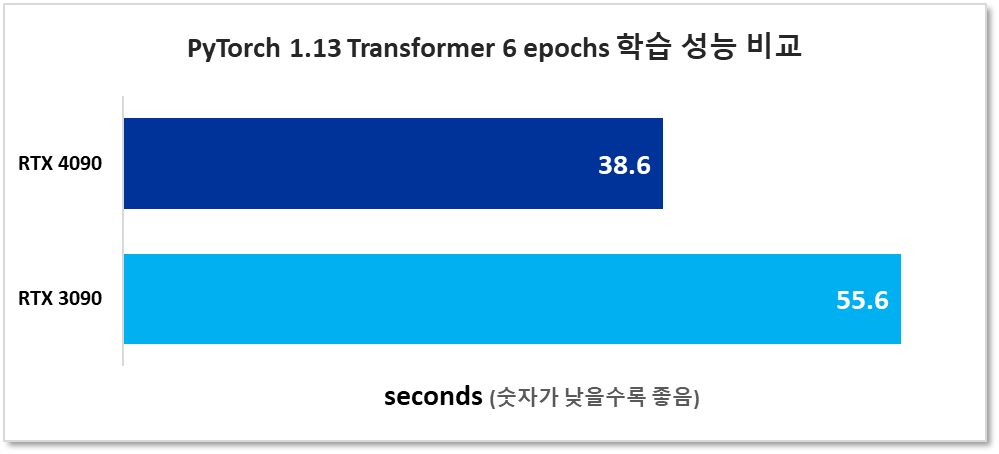
노트:
- CUDA 12가 출시된 후 듀얼 GPU로 이 벤치마크와 기타 Transformer 모델을 실행하여 NVLINK가 없는 RTX 3090 및 RTX 4090의 성능을 테스트할 계획입니다 (NVLINK는 Lovelace arch RTX GPU에서는 사용할 수 없습니다).
https://github.com/pytorch/examples/tree/main/word_language_model
결론
NVIDIA RTX 4090은 RTX 3090에 비해 상당한 성능 향상을 보여 주었습니다. Ada Lovelace 및 Hopper arch GPU를 완벽하게 지원하는 CUDA 12에 대해 컴파일된 코드를 사용하면 결과가 더 좋을 것으로 기대됩니다.
한 가지 놀라운 결과는 RTX 4090의 배정밀도 부동 소수점 (fp64)이 Nvidia가 주요 특장점으로 강조하는 기능이 아님에도 불구하고 상당히 좋다는 것이었습니다. 이러한 GPU의 경우 단정밀도 fp32가 일반적으로 fp64의 20배이지만 RTX 4090의 fp64 성능은 16-34 코어 CPU와 비교해도 충분히 경쟁력이 있었습니다. A100 및 H100과 같은 하이엔드 컴퓨팅 GPU에서 실행하기 위한 코드 테스트 및 개발에 사용할 수 있다고 생각합니다.