





머신러닝을 활용하여 비디오에서 의심스러운 동작을 식별하는 법
사진촬영과 영상녹화가 기하급수적으로 증가함에 따라 비디오 식별 및 분류 프로세스를 운영하고 자동화하는 것이 점점 더 중요해지고 있습니다. 고양이가 촬영된 비디오를 식별하는 것부터 물체를 시각적으로 분류하는 것에 이르기까지 다양한 응용 프로그램이 점점 더 보편화되고 있습니다. 전 세계 수백만 명의 사용자가 매일 수십억 분의 비디오를 생성하고 소비하기 때문에 이러한 대규모 영상을 처리할 수 있는 인프라가 필요합니다.
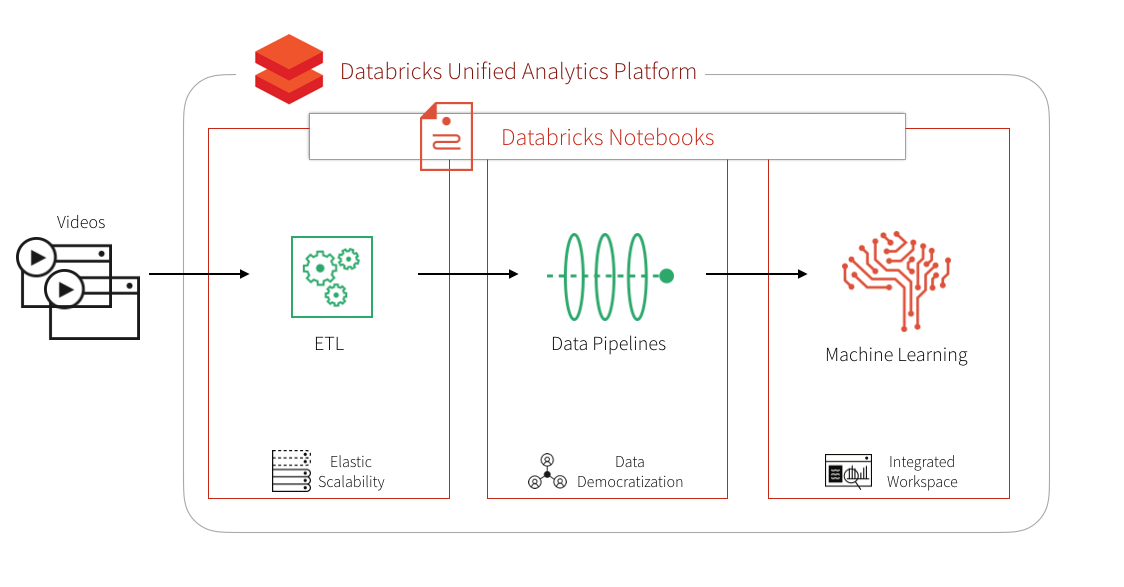
빠르게 확장 가능한 인프라, 여러 머신러닝 및 딥 러닝 패키지 관리, 고성능 수학적 컴퓨팅의 복잡성으로 인해 비디오 처리는 복잡하고 혼란스러울 수 있습니다. 이러한 이유로 데이터 과학자 및 엔지니어는 다음과 같은 아키텍처 관련 문제에 계속 직면하게 됩니다.
- 인프라를 구축할 때 얼마나 확장 가능할까요?
- 다양한 머신러닝 및 딥 러닝 패키지를 통합, 유지 관리 및 최적화하려면 어떻게해야합니까?
- 데이터 엔지니어, 데이터 분석가, 데이터 과학자 및 비즈니스 이해 관계자는 어떻게 협력해야 할까요?
이 블로그에서는 분산 컴퓨팅을 Apache Spark 및 딥 러닝 파이프라인(Keras, TensorFlow 및 Spark 딥 러닝 파이프라인)과 머신러닝을 위한 Databricks 런타임과 결합하여 의심스러운 비디오를 분류하고 식별하는 방법을 보여 줍니다.
의심스러운 동영상 분류
이 시나리오에서는 EC Funded CAVIAR 프로젝트/IST 2001 37540 데이터 세트의 비디오 세트가 있습니다. 우리는 INRIA (1st Set)의 클립을 다음과 같은 CAVIAR 팀원들이 수행 한 여섯 가지 기본 시나리오와 함께 사용하고 있습니다.
- 걷기
- 검색
- 휴식 중, 주저앉아 있거나 실신상태
- 가방을 남겨 두기
- 그룹 회의, 함께 걷다가 헤어짐
- 싸우는 두 사람
이 블로그 게시물 및 관련 비디오 Databricks 노트북의 의심스러운 동작 식별에서는 전처리, 이미지 기능 추출 및 이러한 비디오에 대한 머신러닝을 적용합니다.

출처 : CAVIAR 회원들의 전투 장면 재현 – EC Funded CAVIAR 프로젝트 / IST 2001 37540 http://groups.inf.ed.ac.uk/vision/CAVIAR/CAVIARDATA1/
예를 들어 교육 비디오 데이터 세트에서 추출한 다른 이미지 집합에 대해 학습된 머신러닝 모델을 적용하여 테스트 데이터 세트(예: 위 비디오)에서 추출한 의심스러운 이미지(예: 아래 이미지)를 식별합니다.

고급 데이터 흐름
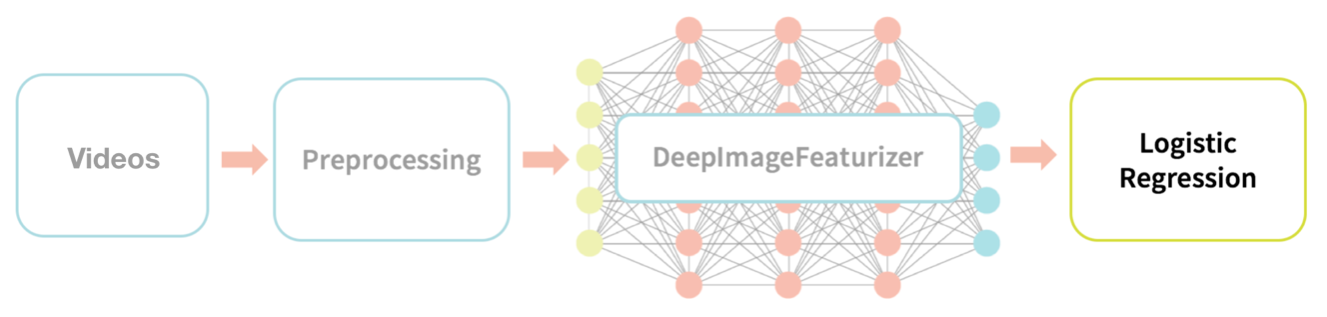
아래 그래픽은 소스 비디오를 로지스틱 회귀 모델의 교육 및 테스트에 처리하기 위한 상위 수준 데이터 흐름을 설명합니다.
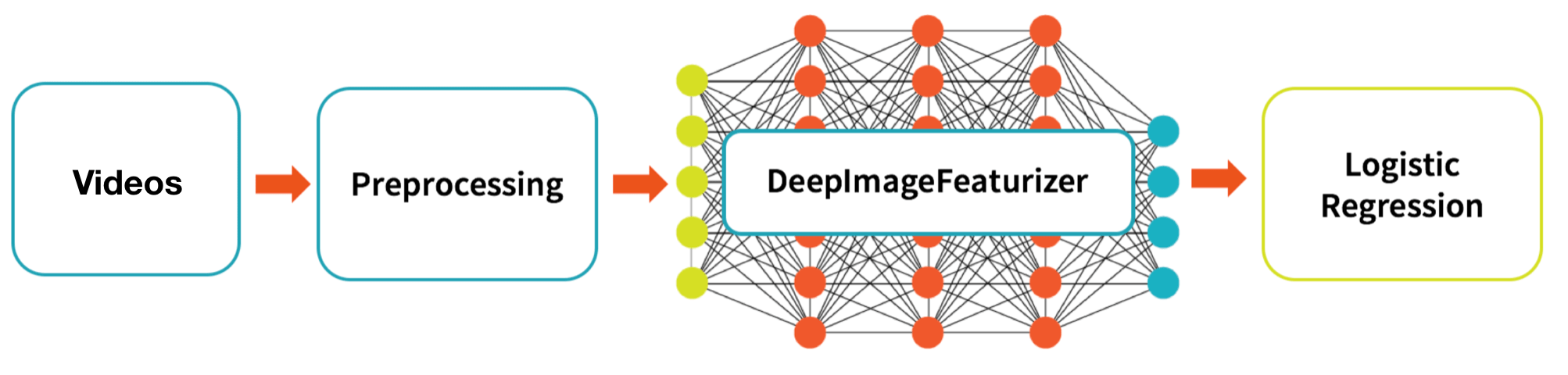
우리가 수행할 상위 수준의 데이터 흐름은 다음과 같습니다.
- 비디오: EC Funded CAVIAR 프로젝트/IST 2001 INRIA의 37540 클립(1st 비디오)을 교육 및 테스트 데이터 세트(예: 교육 및 테스트 비디오 세트)로 활용합니다.
- 전처리: 해당 비디오에서 이미지를 추출하여 일련의 학습 및 테스트 이미지 집합을 만듭니다.
- DeepImageFeaturizer: Spark Deep Learning Pipeline의 DeepImageFeaturizer를 사용하여 이미지 기능의 학습 및 테스트 세트를 만듭니다.
- 로지스틱 회귀: 그런 다음 로지스틱 회귀 모델을 학습하고 적용시켜 의심스러운 이미지 기능과 의심스럽지 않은 이미지 기능(궁극적으로 비디오 세그먼트)을 분류합니다.
여기에 필요한 라이브러리는 다음과 같습니다.
- h5py
- TensorFlow
- Keras
- Spark Deep Learning Pipelines
- TensorFrames
- OpenCV
ML용 Databricks 런타임을 사용하면 OpenCV를 제외한 모든 항목이 이미 사전 설치되어 있으며 Keras, TensorFlow 및 Spark Deep Learning Pipepline을 사용하여 딥 러닝 파이프라인을 실행하도록 구성되어 있습니다. Databricks를 사용하면 자동 크기 조정, 여러 클러스터 유형을 선택할 수 있는 클러스터, 공동 작업 및 다국어 지원을 포함한 Databricks 작업 공간 환경, 모든 분석 요구 사항을 종단간 해결할 수 있는 Databricks 통합 분석 플랫폼의 이점도 누릴 수 있습니다.
소스 비디오
비디오 처리를 빠르게 시작할 수 있도록 CAVIAR 클립을 INRIA(1st Set) 비디오[EC Funded CAVIAR project/IST 2001 37540] 에서 /databricks-datasets로 복사했습니다.
https://www.youtube.com/watch?v=TMyqwGpdIRI
- 교육 동영상():
srcVideoPath/databricks-datasets/cctvVideos/train/ - 테스트 비디오 (:
srcTestVideoPath)/databricks-datasets/cctvVideos/test/ - 레이블이 지정된 데이터(:
labeledDataPath)/databricks-datasets/cctvVideos/labels/cctvFrames_train_labels.csv
전처리
 우리는 궁극적으로 비디오의 개별 이미지의 특징에 대해 머신러닝 모델 (로지스틱 회귀)을 실행할 것입니다. 첫번째 (전처리) 단계는 비디오에서 개별 이미지를 추출하는 것입니다. Databricks 노트북에 포함된 한 가지 방법은 다음 코드 조각에 설명된 대로 OpenCV를 사용하여 초당 이미지를 추출하는 것입니다.
우리는 궁극적으로 비디오의 개별 이미지의 특징에 대해 머신러닝 모델 (로지스틱 회귀)을 실행할 것입니다. 첫번째 (전처리) 단계는 비디오에서 개별 이미지를 추출하는 것입니다. Databricks 노트북에 포함된 한 가지 방법은 다음 코드 조각에 설명된 대로 OpenCV를 사용하여 초당 이미지를 추출하는 것입니다.
## Extract one video frame per second and save frame as JPG
def extractImages(pathIn):
count = 0
srcVideos = "/dbfs" + src + "(.*).mpg"
p = re.compile(srcVideos)
vidName = str(p.search(pathIn).group(1))
vidcap = cv2.VideoCapture(pathIn)
success,image = vidcap.read()
success = True
while success:
vidcap.set(cv2.CAP_PROP_POS_MSEC,(count*1000))
success,image = vidcap.read()
print ('Read a new frame: ', success)
cv2.imwrite("/dbfs" + tgt + vidName + "frame%04d.jpg" % count, image) # save frame as JPEG file
count = count + 1
print ('Wrote a new frame')
이 경우 dbfs 위치에서 비디오를 추출하고 OpenCV의 VideoCapture 메서드를 사용하여 이미지 프레임 (1000ms마다 촬영)을 만들고 해당 이미지를 dbfs에 저장합니다. 전체 코드 예제는 비디오 Databricks 노트북의 의심스러운 동작 식별에서 찾을 수 있습니다.
이미지를 추출한 후에는 다음 코드 조각을 사용하여 추출된 이미지를 읽고 볼 수 있습니다.
from pyspark.ml.image import ImageSchema
trainImages = ImageSchema.readImages(targetImgPath)
display(trainImages)겨결과물은 아래 스크린샷과 같습니다.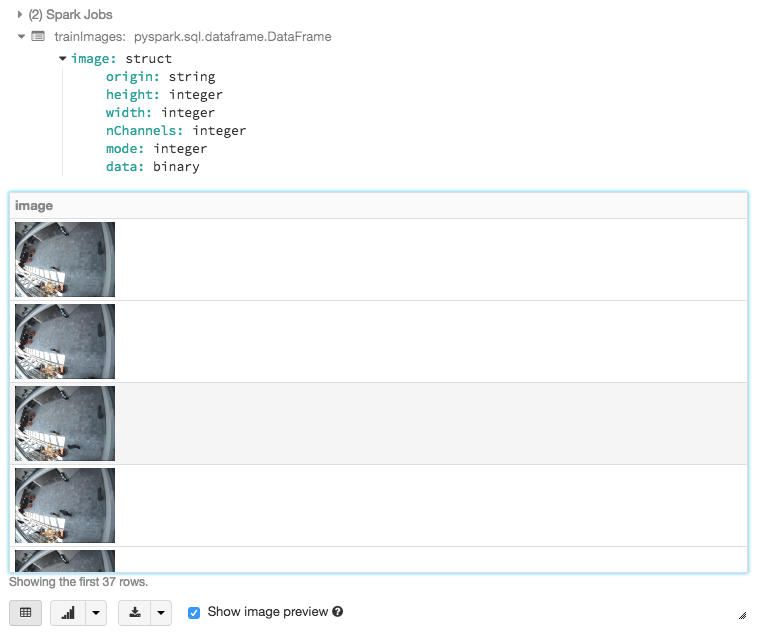
참고로, 우리는 비디오의 교육 및 테스트 세트 전부에서 이 작업을 수행합니다.
DeepImageFeaturizer
딥 러닝을 위한 전이 학습 소개에서 언급했듯이, 이전 학습은 한 작업(예 : 자동차 이미지 식별)에 대해 훈련된 모델이 다른 관련 작업 (예 : 트럭 이미지 식별)에서 다시 사용되는 기술입니다. 이 시나리오에서는 Spark Deep Learning Pipeline을 사용하여 이미지에 대한 전송 학습을 수행합니다.
출처: TensorFlow의 시작
다음 코드 조각에서 언급했듯이 Inception V3 모델(TensorFlow의 Inception in TensorFlow)을 사용하여 미리 학습된 신경망의 마지막 계층을 자동으로 추출하여 이러한 이미지를 숫자 기능으로 변환합니다.
DeepImageFeaturizer
# Build featurizer using DeepImageFeaturizer and InceptionV3
featurizer = DeepImageFeaturizer( \
inputCol="image", \
outputCol="features", \
modelName="InceptionV3" \
)
# Transform images to pull out
# - image (origin, height, width, nChannels, mode, data)
# - and features (udt)
features = featurizer.transform(images)
# Push feature information into Parquet file format
features.select( \
"Image.origin", "features" \
).coalesce(2).write.mode("overwrite").parquet(filePath)
이미지의 학습 및 테스트 세트 (해당 비디오에서 제공됨)는 모두 DeepImageFeaturizer에 의해 처리되고 궁극적으로 Parquet 파일에 저장됩니다.
로지스틱 회귀 분석
이전 단계에서는 소스 교육 및 테스트 비디오를 이미지로 변환한 다음 OpenCV 및 Spark 딥 러닝 파이프라인 DeepImageFeaturizer(Inception V3 포함)를 사용하여 Parquet 형식으로 기능을 추출하고 저장하는 과정을 거쳤습니다. 이 시점에서 이제 ML 모델에 적합하고 테스트할 수 있는 숫자 기능 집합이 있습니다. 교육 및 테스트 데이터 세트가 있고 이미지(및 관련 비디오)가 의심스러운지 여부를 분류하려고 하기 때문에 로지스틱 회귀를 시도할 수 있는 분류(Supervised classification) 문제가 있습니다.
이 사용 사례는 원본 데이터 세트에 포함된 레이블이 지정된 데이터 CSV 파일(이미지 프레임 이름 및 의심스러운 플래그의 매핑)이 포함되어 있기 때문에 지도학습(Supervised machine learning)이 적용됩니다. 다음 코드 조각은 손으로 레이블이 지정된 이 데이터()를 읽고 이를 학습 기능 Parquet 파일()에 조인하여 학습 데이터 세트를 만듭니다.
labeledDataPathlabels_dffeatureDF
# Read in hand-labeled data
from pyspark.sql.functions import expr
labels = spark.read.csv( \
labeledDataPath, header=True, inferSchema=True \
)
labels_df = labels.withColumn(
"filePath", expr("concat('" + prefix + "', ImageName)") \
).drop('ImageName')
# Read in features data (saved in Parquet format)
featureDF = spark.read.parquet(imgFeaturesPath)
# Create train-ing dataset by joining labels and features
train = featureDF.join( \
labels_df, featureDF.origin == labels_df.filePath \
).select("features", "label", featureDF.origin)
이제 다음 코드 조각에 설명된 대로 이 데이터 세트에 대해 로지스틱 회귀 모델()을 맞출 수 있습니다.
lrModel
from pyspark.ml.classification import LogisticRegression
# Fit LogisticRegression Model
lr = LogisticRegression( \
maxIter=20, regParam=0.05, elasticNetParam=0.3, labelCol="label")
lrModel = lr.fit(train)
모델을 학습한 후 이제 테스트 데이터 세트에 대한 예측을 생성할 수 있습니다. 즉, LR 모델이 의심스러운 것으로 분류되는 테스트 비디오를 예측하도록 할 수 있습니다. 다음 코드 조각에서 언급했듯이 Parquet에서 테스트 데이터()를 로드한 다음 이전에 학습된 모델()을 사용하여 테스트 데이터()에 대한 예측을 생성합니다.
featuresTestDFresultlrModel
from pyspark.ml.classification import LogisticRegression, LogisticRegressionModel
# Load Test Data
featuresTestDF = spark.read.parquet(imgFeaturesTestPath)
# Generate predictions on test data
result = lrModel.transform(featuresTestDF)
result.createOrReplaceTempView("result")
이제 테스트 실행에서 벡터를 얻었으므로 벡터의 두 번째 요소 ()를 추출하여 정렬 할 수도 있습니다.
resultsprob2probability
from pyspark.sql.functions import udf
from pyspark.sql.types import FloatType
# Extract first and second elements of the StructType
firstelement=udf(lambda v:float(v[0]),FloatType())
secondelement=udf(lambda v:float(v[1]),FloatType())
# Second element is what we need for probability
predictions = result.withColumn("prob2", secondelement('probability'))
predictions.createOrReplaceTempView("predictions")
이 예제에서 예측의 첫 번째 행인 DataFrame은 이미지를 prediction = 0 즉, 의심스럽지 않은 것으로 분류합니다. 이진 로지스틱 회귀를 사용할 때 (firstelement, secondelement)의 확률 StructType은 (probability of prediction = 0, probability of prediction = 1)을 의미합니다. 따라서, 의심스러운 이미지를 검토하여 두 번째 요소 (prob2)에 따라 정렬합니다.
다음 Spark SQL 쿼리를 실행하여 where prediction = 1prob2에 따라 정렬시킨 의심스러운 이미지()를 검토할 수 있습니다.
%sql
select origin, probability, prob2, prediction from predictions where prediction = 1 order by prob2 desc
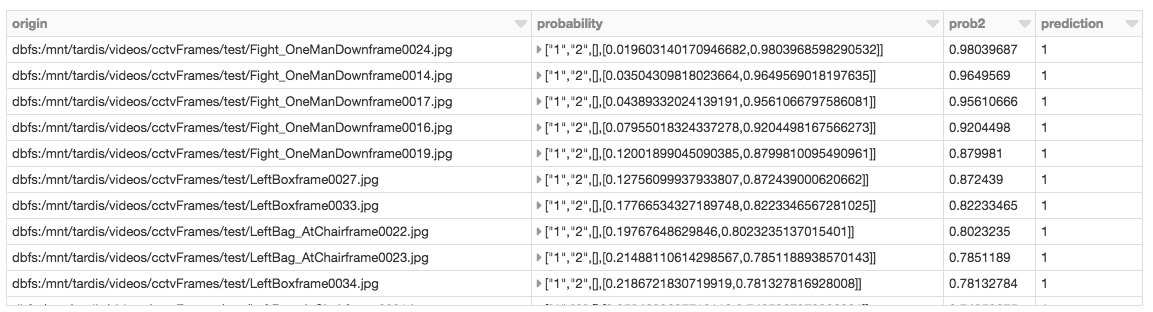
위의 결과를 바탕으로 이제 의심스러운 것으로 분류 된 상위 3개의 프레임을 볼 수 있습니다.
displayImg("dbfs:/mnt/tardis/videos/cctvFrames/test/Fight_OneManDownframe0024.jpg")

displayImg("dbfs:/mnt/tardis/videos/cctvFrames/test/Fight_OneManDownframe0014.jpg")
displayImg("dbfs:/mnt/tardis/videos/cctvFrames/test/Fight_OneManDownframe0017.jpg")

결과에 따라 아래에 설명된 대로 비디오를 신속하게 식별할 수 있습니다.
displayDbfsVid("databricks-datasets/cctvVideos/mp4/test/Fight_OneManDown.mp4")
요약
마지막으로 Databricks Unified Analytics Platform: ML 모델, 비디오 및 추출된 이미지의 공동 작업 및 시각화를 허용하는 Databricks 작업 영역, Keras, TensorFlow, TensorFrames로 미리 구성된 머신러닝을 위한 Databricks 런타임 및 기타 머신러닝 및 딥 러닝 라이브러리를 사용하여 의심스러운 비디오를 분류하고 식별하는 방법을 시연하여 이러한 다양한 라이브러리의 유지 관리를 간소화했습니다. GPU를 지원하는 클러스터의 자동 크기 조정을 최적화하여 고성능 수치 컴퓨팅을 확장할 수 있었습니다. 이러한 구성 요소를 함께 배치하면 사용자와 데이터 실무자를 위한 비디오 분류(및 기타 머신러닝 및 딥 러닝 문제)의 데이터 흐름 및 관리가 간소화됩니다.