





머신러닝 적용사례 제 6장. 자동차 분류를 위한 컨볼루션 신경망 구현
CNN(Convolutional
Neural Networks)은 주로 컴퓨터 비전 작업에 사용되는 최첨단 신경망 아키텍처입니다. CNN은 이미지 인식, 객체 위치 파악 및 변경 감지와 같은 다양한 작업에 적용될 수 있습니다. 최근에 파트너인 Data Insights는 자동차 제조업체로부터 주어진 이미지에서 자동차 모델을 식별할 수 있는 Computer Vision 응용 프로그램을 개발해 달라는 요청을 받았습니다. 자동차 모델이 달라도 아주 비슷하게 보일 수 있고 어떤 자동차라도 주변 환경과 사진을 찍는 각도에 따라 매우 다르게 보일 수 있다는 점을 고려할 때 이러한 작업은 최근까지만 해도 불가능했습니다.

하지만 2012년경부터 딥러닝 혁명이 일어나면서 이러한 문제를 해결할 수 있게 되었습니다.
컴퓨터는 자동차의 개념을 설명하는 대신 그림을 반복적으로 연구하고 그러한 개념을 스스로 학습할 수 있습니다.
지난 몇 년 동안 추가적인 인공 신경망 혁신으로 인해 인간 수준의 정확도로 이미지 분류 작업을 수행할 수 있는
AI가 탄생했습니다.
이러한 개발을 기반으로
Deep CNN을 학습하여 모델별로 자동차를 분류할 수 있었습니다.
신경망은
196개의 서로 다른 모델로 구성된
16,000개 이상의 자동차 사진이 포함된
Stanford Cars Data Set에서 학습되었습니다. 시간이 지남에 따라 신경망이 자동차의 개념과 다양한 모델을 구별하는 방법을 학습함에 따라 예측의 정확도가 향상되기 시작하는 것을 볼 수 있었습니다.
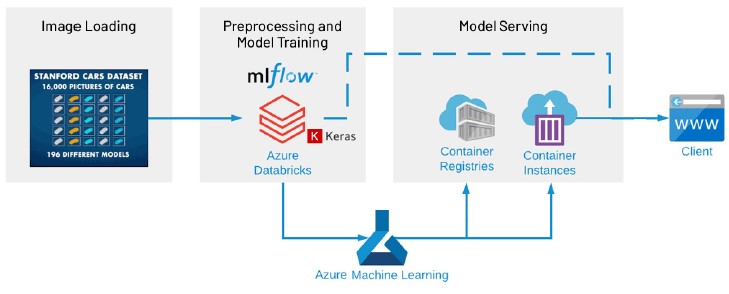
우리는 데이터 전처리를 위한
Apache Spark™ 및
Koalas, 모델 학습을 위한
Keras와
Tensorflow, 모델 및 결과의 추적을 위한
MLflow, REST 서비스의 배포를 위한
Azure ML을 사용하여 종단 간 머신러닝 파이프라인을 구축했습니다.
Azure Databricks 내의 이
설정은 네트워크를 빠르고 효율적으로 학습하도록 최적화되어 있으며 다양한
CNN 구성을 훨씬 더 빠르게 시도하는 데도 도움이 됩니다.
몇 번만 연습해도
CNN의 정확도는 약
85%에 달했습니다.
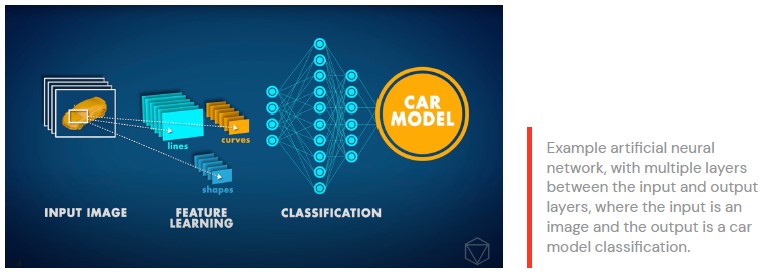
이미지 분류를 위한 인공 신경망 설정
이 글에서 우리는 신경망을 운영하는 데 사용되는 몇 가지 주요 기술의 개요를 설명합니다.
신경망을 직접 실행해보고 싶다면 세심한 단계별 가이드가 포함된 전체 노트북을 아래에서 찾을 수 있습니다.
이 데모는 공개적으로 사용 가능한
Stanford Cars Data Set를
사용합니다.
약간 오래된 데이터라서 2012년
이후에 생산된 자동차 모델을 찾을 수 없긴 하지만 일단 학습이 되기만 하면 전이학습을 통해 새로운 데이터 세트로 쉽게 대체가 가능합니다.
데이터는 작업 영역에 마운트할 수 있는
ADLS Gen2 스토리지 계정을 통해 제공됩니다.

데이터 전처리의 첫 번째 단계에서 이미지는
hdf5 파일로 압축됩니다(하나는 학습용,
하나는 테스트용).
그런 다음 신경망에서 읽을 수 있습니다.
hdf5 파일은 제공된 노트북의 일부로 제공되는
ADLS Gen2 스토리지의 일부이므로 원하는 경우 이 단계를 완전히 생략할 수 있습니다.
n Stanford
Cars 데이터 세트를
HDF5 파일로 로드
n 이미지 확대를 위해 코알라 사용
n Keras로
CNN 학습
n Azure
ML에
REST 서비스로 모델 배포
코알라를 이용한 이미지 강화
수집된 데이터의 양과 다양성은 딥 러닝 모델로 달성할 수 있는 결과에 큰 영향을 미칩니다.
데이터 강화는 실제로 새로운 데이터를 수집할 필요 없이 학습 결과를 크게 향상시킬 수 있는 전략입니다.
대규모 신경망을 학습하는 데 일반적으로 사용되는 자르기,
패딩 및 수평 뒤집기와 같은 다양한 기술을 사용하면 학습 및 테스트용 이미지 수를 늘려 데이터 세트를 인위적으로 부풀릴 수 있습니다.
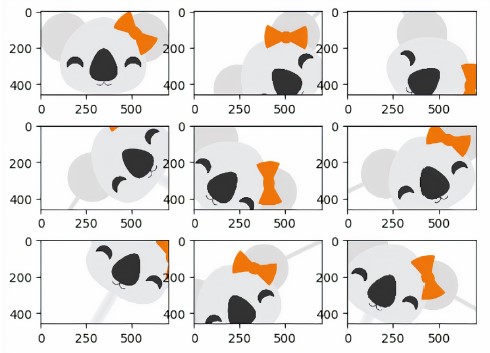
대규모 학습 데이터에 강화를 적용하는 것은 다른 접근 방식의 결과와 비교할 때 비용이 매우 많이 들 수 있습니다.
코알라를 사용하면
Python에서 이미지 강화를 위한 기존 프레임워크를 쉽게 시도하고
pandas API에 익숙한 데이터 과학을 사용하여 여러 노드가 있는 클러스터에서 프로세스를 확장할 수 있습니다.
Keras에서 ResNet 코딩
CNN을 분리하면 여러
“블록“으로 구성되며 각 블록은 단순히 일부 입력 데이터에 적용할 작업 그룹을 나타냅니다.
이러한 블록은 크게 다음과 같이 분류할 수 있습니다.
n ID
블록:
데이터의 모양을 동일하게 유지하는 일련의 작업
n Convolution
Block: 입력 데이터의 모양을 더 작은 모양으로 줄이는 일련의 작업
CNN은 일련의 식별 블록과 컨볼루션 블록(또는
ConvBlock)으로 입력 이미지를 숫자의 압축된 그룹으로 축소합니다.
이러한 각각의 결과 숫자(올바르게 학습된 경우)는 결국 이미지 분류에 유용한 정보를 알려줄 것입니다.
잔여
CNN은 각 블록에 대해 추가 단계를 추가합니다.
데이터는 블록을 구성하는 연산이 적용되기 전에 임시 변수로 저장되고 이 임시 데이터가 출력 데이터에 추가됩니다.
일반적으로 이 추가 단계는 각 블록에 적용됩니다.
예를 들어 아래 그림은 손으로 쓴 숫자를 감지하는 단순화된
CNN을 보여줍니다.
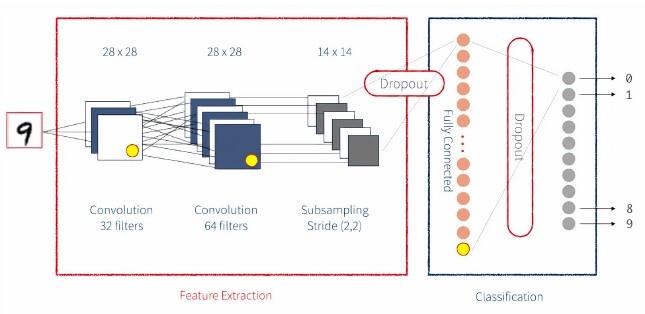
신경망을 구현하는 방법에는 여러 가지가 있습니다. 보다 직관적인 방법 중 하나는 Keras를 사용하는 것입니다. Keras는 신경망을 구성하는 개별 단계를 실행하기 위한 간단한 프런트 엔드 라이브러리를 제공합니다. Keras는 Tensorflow 백엔드 또는 Theano 백엔드와 함께 작동하도록 구성할 수 있습니다. 여기서는 Tensorflow 백엔드를 사용할 것입니다. Keras 네트워크는 아래와 같이 여러 계층으로 나뉩니다.
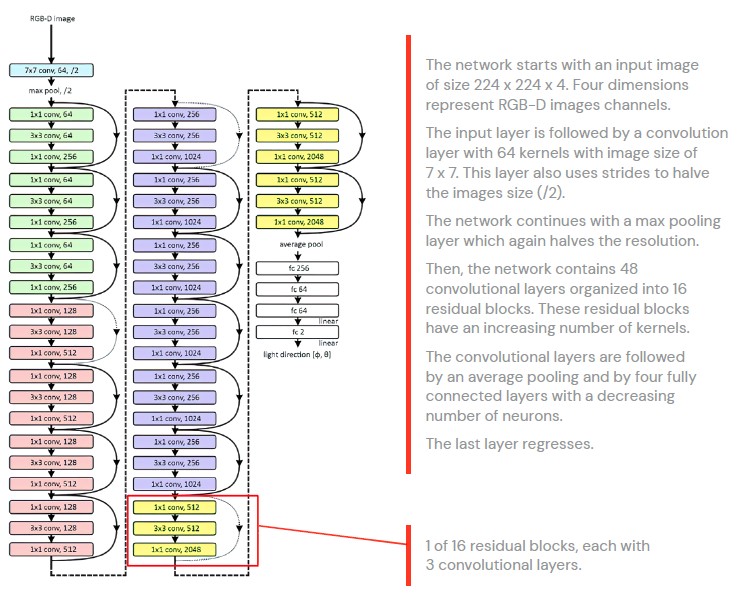
스케일 레이어
trainable
weights가 있는 모든 사용자 지정 작업의 경우
Keras를 사용하면 고유한 계층을 구현할 수 있습니다.
엄청난 양의 이미지 데이터를 처리할 때 메모리 문제가 발생할 수 있습니다.
처음에
RGB 이미지에는 정수 데이터(0-255)가 포함됩니다.
역전파 동안 최적화 작업의 일환으로 경사 하강법을 실행할 때 정수 기울기는
network weights를
적절하게 조정하기에 충분한 정확도를 허용하지 않는다는 것을 알게 될 것입니다.
따라서 부동 소수점 정밀도로 변경해야 합니다.
여기서 문제가 발생할 수 있습니다.
이미지를
224 x 224 x 3으로 축소하더라도
10,000개의 학습 이미지를 사용할 때
10억 개 이상의 부동 소수점 항목을 보게 됩니다.
전체 데이터 세트를 부동 소수점 정밀도로 바꾸는 것과 반대로,
더 나은 방법은 입력 데이터를 한 번에 한 이미지씩 필요할 때만 크기를 조정하는
“크기 조정 레이어“를 사용하는 것입니다.
이는 모델에서
Batch Normalization 후에 적용해야 합니다. 이 Scale 레이어의 매개변수도 학습을 통해 학습할 수 있는 매개변수입니다.
스코어링 중에도 이 사용자 정의 레이어를 사용하려면 클래스를 모델과 함께 패키징해야 합니다.
MLflow를 사용하면 이름(문자열)을
Keras 모델과 연결된 사용자 지정 클래스 또는 함수에 매핑하는
Keras custom_objects 사전을 사용하여 이를 달성할 수
있습니다.
MLflow는
CloudPickle을 사용하여 이러한 사용자 지정 레이어를 저장하고 모델이
mlflow.keras.load_model() 및 mlflow.pyfunc.load_model()로 로드될 때 자동으로 복원합니다.

MLflow 및 Azure Machine Learning으로 결과 추적
머신러닝 개발에는 소프트웨어 개발 외에 추가적인 복잡성이 포함됩니다.
무수히 많은 도구와 프레임워크가 있기 때문에 실험을 추적하고 결과를 재현하며 머신러닝 모델을 배포하기가 어렵습니다.
Azure Machine Learning과
함께
MLflow를 사용하여 종단 간 머신러닝 수명 주기를 가속화하고 관리하여
Azure Databricks를
사용하여 머신러닝 애플리케이션을 안정적으로 빌드,
공유 및 배포할 수 있습니다.
결과를 자동으로 추적하기 위해 기존 또는 새
Azure ML 작업 영역을
Azure Databricks 작업 영역에 연결할 수
있습니다.
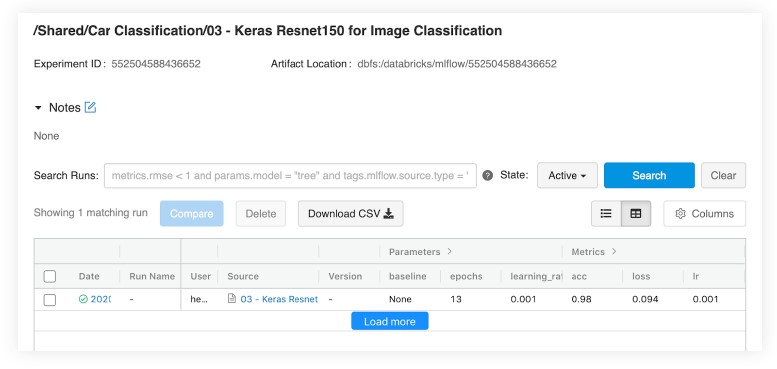
또한
MLflow는
Keras 모델(mlflow.keras.autolog())에 대한 자동 로깅을 지원하므로 훨씬 수월합니다.
MLflow의 기본 제공 모델 지속성 유틸리티는
Keras와 같이 널리 사용되는 다양한
ML 라이브러리의 모델을 패키징하는 데 편리하지만 모든 사용 사례를 다루지는 않습니다.
예를 들어
MLflow의 기본 제공 버전에서 명시적으로 지원하지 않는
ML 라이브러리의 모델을 사용하려고 할 수 있습니다.
또는 사용자 지정 추론 코드와 데이터를 패키징하여
MLflow 모델을 생성할 수 있습니다.
다행히
MLflow는 이러한 작업을 수행하는 데 사용할 수 있는 두 가지 솔루션인 사용자 지정
Python 모델 및 사용자 지정 flavor를
제공합니다.
이 시나리오에서는 REST API 클라이언트의 요청을 지원하는 모델 추론 엔진을 사용할 수 있는지 확인하려고 합니다.
이를 위해 이전에 빌드된
Keras 모델을 기반으로 하는 사용자 지정 모델을 사용하여 내부에
Base64로 인코딩된 이미지가 있는
JSON DataFrame 개체를 허용합니다.


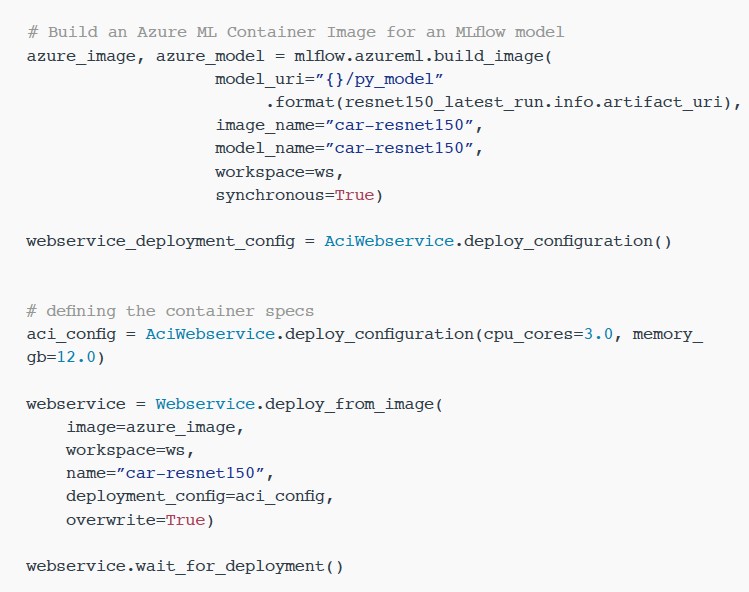
다음 단계에서는 이 py_model을 사용하여 MLflow의 Azure ML를 연동함으로써 Azure Container Instances 서버에 배포할 수 있습니다.
Azure Container Instances에서 이미지 분류 모델 배포
지금까지 학습된 머신러닝 모델이 있고 클라우드의
MLflow를 사용하여 작업 공간에 모델을 등록했습니다.
마지막 단계로 모델을
Azure Container Instances에
웹 서비스로 배포하려고 합니다.
웹 서비스는 이미지(이 경우
Docker 이미지)입니다.
스코어링 로직과 모델 자체를 캡슐화합니다.
이 경우 사용자 지정
MLflow 모델 표현을 사용하고 있습니다.
이를 통해 점수 매기기 논리가
REST 클라이언트에서 이미지를 관리하는 방법과 응답이 형성되는 방법을 제어할 수 있습니다.
컨테이너 인스턴스는 워크플로를 테스트하고 이해하기 위한 훌륭한 솔루션입니다.
확장 가능한 프로덕션 배포의 경우
Azure Kubernetes Service 사용을 고려하세요. 자세한 내용은 배포 방법 및 위치를 참조하세요.
CNN 이미지 분류 시작하기
이 문서와 노트북은 종단 간 워크플로 교육을 설정하고
Azure의 프로덕션 환경에 신경망을 배포하는 데 사용되는 주요 기술을 보여줍니다.
연결된 노트북의 연습에서는
Keras, Databricks Koalas, MLflow 및 Azure ML과 같은 도구를 사용하여 고유한
Azure Databricks 환경 내에서 이를 만드는 데
필요한 단계를 안내합니다.
개발자 리소스
n 노트북:
ü Stanford
Cars 데이터 세트를 HDF5 파일로 로드
n 비디오:
Databricks에서 Deep
Convolutional Neural Networks를 사용한 AI 자동차 분류
n GitHub:
EvanEames
| 자동차
n 슬라이드:
자동차 분류를 위한 컨볼루션 신경망 구현
n PDF:
Databricks에 대한 컨볼루션 신경망 구현