





Python에서 베이지안 최적화(Bayesian optimization)를 구현하는 방법
이 자습서에서는 복잡한 최적화 문제에 대해 베이지안 최적화 알고리즘을 구현하는 방법을 알아봅니다.
전역 최적화는 주어진 목적 함수의 최소 또는 최대 비용을 초래하는 입력값을 찾는 어려운 문제입니다.
일반적으로 목적 함수의 형식은 분석하기가 복잡하고 다루기 어려우며 종종 볼록하지 않고, 비선형이며, 고차원이고, 노이즈가 많고, 계산 비용이 많이 듭니다.
베이지안 최적화는 효율적이고 효과적인 전역 최적화 문제를 검색하도록 지시하는 Bayes 정리를 기반으로 하는 원칙적인 기술을 제공합니다. 대리 함수라고 하는 목적 함수의 확률적 모델을 구축한 다음 실제 목적 함수에 대한 평가를 위해 후보 샘플을 선택하기 전에 획득 함수로 효율적으로 검색합니다.
베이지안 최적화는 응용 머신러닝에서 검증 데이터 세트에서 성능이 좋은 특정 모델의 하이퍼파라미터를 조정하는 데 자주 사용됩니다.
이 자습서를 완료하면 다음을 알 수 있습니다.
- 글로벌 최적화는 블랙 박스와 종종 볼록하지 않고, 비선형이며, 노이즈가 많고, 계산 비용이 많이 드는 목적 함수를 포함하는 어려운 문제입니다.
- 베이지안 최적화는 전역 최적화를 위한 확률적으로 원칙적인 방법을 제공합니다.
- 베이지안 최적화를 처음부터 구현하는 방법과 오픈 소스 구현을 사용하는 방법.
튜토리얼 개요
이 자습서는 다음과 같이 네 부분으로 나뉩니다.
- 기능 최적화의 과제
- 베이지안 최적화란?
- 베이지안 최적화를 수행하는 방법
- 베이지안 최적화를 사용한 하이퍼 파라미터 튜닝
기능 최적화의 과제
전역 함수 최적화 또는 줄여서 함수 최적화는 목적 함수의 최소값 또는 최대값을 찾는 것을 포함합니다.
샘플은 도메인에서 추출되고 목적 함수에 의해 평가되어 점수 또는 비용을 제공합니다.
몇 가지 일반적인 용어를 정의해 보겠습니다.
- 샘플: 벡터로 표현되는 도메인의 한 가지 예입니다.
- 검색 공간: 샘플을 가져올 수 있는 도메인의 범위입니다.
- 목적 함수: 샘플을 가져와 비용을 반환하는 함수입니다.
- 비용: 목적 함수를 통해 계산된 표본의 숫자 점수입니다.
샘플은 일반적으로 고안하거나 만들기 쉬운 하나 이상의 변수로 구성됩니다. 하나의 샘플은 종종 n차원 공간에서 미리 정의된 범위를 가진 변수로 구성된 벡터로 정의됩니다. 이 공간은 최상의 비용을 초래하는 변수 값의 특정 조합을 찾기 위해 샘플링하고 탐색해야 합니다.
비용에는 지정된 도메인과 관련된 단위가 있는 경우가 많습니다. 최적화는 종종 비용 최소화의 관점에서 설명되는데, 최대화 문제는 계산된 비용을 반전시켜 최소화 문제로 쉽게 변환할 수 있기 때문입니다. 함께 함수의 최소값과 최대값을 함수의 극값(또는 복수 극값)이라고 합니다.
목적 함수는 지정하기 쉬운 경우가 많지만 계산하기 어렵거나 시간 경과에 따른 비용 계산에 노이즈가 발생할 수 있습니다. 목적 함수의 형태는 알려지지 않았으며 종종 매우 비선형적이며 입력 변수의 수로 정의되는 매우 다차원적인 것입니다. 이 기능은 또한 볼록하지 않을 수도 있습니다. 즉, 로컬 극값(extrema)은 전역 극값일 수도 있고 아닐 수도 있으므로(예: 오해의 소지가 있고 조기 수렴을 초래할 수 있음) 작업 이름은 로컬 최적화가 아닌 전역 최적화입니다.
목적 함수에 대해서는 알려진 바가 거의 없지만(함수에서 최소 또는 최대 비용을 찾는지 여부를 알 수 있음) 따라서 종종 블랙박스 함수라고 하고 검색 프로세스를 블랙박스 최적화라고 합니다. 또한 목적 함수는 답변만 제공할 수 있는 기능이 주어지면 오라클이라고도 합니다.
함수 최적화는 머신러닝의 기본적인 부분입니다. 대부분의 머신러닝 알고리즘에는 학습 데이터에 대한 응답으로 매개 변수(가중치, 계수 등)의 최적화가 포함됩니다. 최적화는 머신러닝 알고리즘의 학습을 구성하는 최상의 하이퍼 매개 변수 집합을 찾는 프로세스도 나타냅니다. 다시 한 단계 더 나아가 훈련 데이터, 데이터 준비 및 머신러닝 알고리즘 자체의 선택도 기능 최적화의 문제입니다.
머신러닝의 최적화 요약:
- 알고리즘 교육. 모델 매개 변수의 최적화.
- 알고리즘 튜닝. 모델 하이퍼파라미터 최적화.
- 예측 모델링. 데이터 최적화, 데이터 준비 및 알고리즘 선택.
함수 최적화를 위해 변수 검색 공간을 무작위로 샘플링하거나(임의 검색이라고 함) 검색 공간 전체의 그리드에서 샘플을 체계적으로 평가하는 것과 같은 많은 방법이 있습니다(그리드 검색이라고 함).
보다 원칙적인 방법은 공간 샘플링을 통해 학습할 수 있으므로 향후 샘플이 극값을 포함할 가능성이 가장 높은 검색 공간 부분으로 향하게 됩니다.
확률을 사용하는 전역 최적화에 대한 직접적인 접근 방식을 베이지안 최적화라고 합니다.
베이지안 최적화란?
베이지안 최적화는 목적 함수의 최소값 또는 최대값을 찾기 위해 Bayes 정리를 사용하여 검색을 지시하는 접근 방식입니다.
복잡하고 노이즈가 많거나 평가 비용이 많이 드는 목적 함수에 가장 유용한 접근 방식입니다.
베이지안 최적화는 평가 비용이 많이 드는 목적 함수의 극값을 찾기 위한 강력한 전략입니다. […] 이러한 평가가 비용이 많이 들거나, 파생 상품에 접근할 수 없거나, 당면한 문제가 볼록하지 않을 때 특히 유용합니다.
—고가의 비용 함수의 베이지안 최적화에 대한 자습서, 활성 사용자 모델링 및 계층적 강화 학습에 적용, 2010.
Bayes 정리는 사건의 조건부 확률을 계산하는 접근 방식입니다.
- P(A| B) = P (B| A) * P (A) / P (B)
P(B)의 정규화 값을 제거하여 이 계산을 단순화하고 조건부 확률을 비례 수량으로 설명할 수 있습니다. 이것은 특정 조건부 확률을 계산하는 데 관심이 없고 대신 수량을 최적화하는 데 관심이 있기 때문에 유용합니다.
- P(A| B) = P (B|A) * P (A)
우리가 계산하는 조건부 확률은 일반적으로 사후확률이라고 합니다. 역 조건부 확률은 때때로 발생가능성(Likelihood)이라고 하며 한계 확률은 사전확률이라고 합니다. 예를 들어:
- 사후 = 가능성 * 이전
이것은 도메인에서 샘플을 제공하고 목적 함수를 통한 평가가 주어진 알려지지 않은 목적 함수에 대한 믿음을 정량화하는 데 사용할 수 있는 프레임워크를 제공합니다.
특정 샘플(x1, x2, …, xn)을 고안하고 샘플 xi에 대한 비용 또는 결과를 반환하는 목적 함수f(xi)를 사용하여 평가할 수 있습니다. 샘플과 그 결과는 순차적으로 수집되어 데이터 D를 정의합니다(예:D = {xi, f(xi), … xn, f(xn)} 및 사전을 정의하는 데 사용됩니다. 발생가능성 함수는 함수P(D | f)가 주어진 데이터를 관찰할 확률로 정의됩니다. 이 발생가능성 함수는 관측치가 수집될수록 변경됩니다.
- P(f| D) = P (D|f) * P (f)
사후는 목적 함수에 대해 우리가 알고 있는 모든 것을 나타냅니다. 목적 함수의 근사치이며 평가하려는 다양한 후보 표본의 비용을 추정하는 데 사용할 수 있습니다.
이런 식으로 사후 확률은 대리 목적 함수입니다.
사후는 알려지지 않은 목적 함수에 대한 업데이트 된 믿음을 포착합니다. 베이지안 최적화의 이 단계를 대리 함수(반응 표면이라고도 함)로 목적 함수를 추정하는 것으로 해석할 수도 있습니다.
—고가의 비용 함수의 베이지안 최적화에 대한 자습서, 활성 사용자 모델링 및 계층적 강화 학습에 적용, 2010.
- 대리 함수: 효율적으로 샘플링할 수 있는 목적 함수의 베이지안 근사치입니다.
대리 함수는 목적 함수의 추정치를 제공하며, 이는 향후 샘플링을 지시하는 데 사용할 수 있습니다. 샘플링은 예를 들어 더 많은 샘플을 획득하기 위해 “획득” 기능으로 알려진 기능에서 사후를 신중하게 사용하는 것을 포함합니다. 목적 함수에 대한 믿음을 사용하여 성과를 거둘 가능성이 가장 높은 검색 공간 영역을 샘플링하려고 하므로 획득은 다음 샘플을 생성하기 위해 검색에서 위치의 조건부 확률을 최적화합니다.
- 획득 기능: 검색 공간에서 다음 샘플을 선택하기 위해 사후를 사용하는 기술입니다.
추가 샘플과 목적 함수f()를 통한 평가가 수집되면 데이터D에 추가되고 사후가 업데이트됩니다.
이 과정은 목적 함수의 극값을 찾거나, 충분한 결과를 찾거나, 리소스가 소진될 때까지 반복됩니다.
베이지안 최적화 알고리즘은 다음과 같이 요약할 수 있습니다.
- 1. 획득 기능을 최적화하여 샘플을 선택합니다.
- 2. 목적 함수로 표본을 평가합니다.
- 3. 데이터를 업데이트하고 대리 기능을 업데이트합니다.
- 4. 순서 1로 다시 돌아가기
베이지안 최적화를 수행하는 방법
이 섹션에서는 간단한 1차원 테스트 함수에 대한 구현을 처음부터 개발하여 베이지안 최적화가 작동하는 방식을 살펴보겠습니다.
먼저 테스트 문제를 정의한 다음 대리 함수를 사용하여 입력과 출력의 매핑을 모델링하는 방법을 정의합니다. 다음으로, 이러한 모든 요소를 베이지안 최적화 프로시저에 연결하기 전에 획득 함수를 사용하여 대리 함수를 효율적으로 검색할 수 있는 방법을 살펴보겠습니다.
테스트 문제
첫 번째 단계는 테스트 문제를 정의하는 것입니다.
다음과 같이 계산된 5개의 피크가 있는 다중 모드 문제를 사용합니다.
- y = x^2 * sin(5 * PI * x)^6
여기서x는 [0,1] 범위의 실수 값이고PI는 pi 값입니다.
평균이 0이고 표준 편차가 0.1인 가우스 노이즈를 추가하여 이 함수를 보강합니다. 이는 실제 평가에 양수 또는 음수 임의 값이 추가되어 기능을 최적화하기 어렵게 만든다는 것을 의미합니다.
아래의 objective() 함수는 이를 구현합니다.
먼저 도메인 전체에서 단계 크기가 0.01인 0에서 1까지의 그리드 기반 입력 샘플을 정의하여 이 함수를 테스트할 수 있습니다.
그런 다음 노이즈 없이 목표 함수를 사용하여 이러한 샘플을 평가하여 실제 목적 함수가 어떻게 생겼는지 확인할 수 있습니다.
그런 다음 노이즈로 동일한 점을 평가하여 목적 함수를 최적화할 때 어떤 모습일지 확인할 수 있습니다.
노이즈가 없는 모든 목적 함수 값을 살펴보고 최고 점수를 얻은 입력을 찾아 보고할 수 있습니다. 이것은 목적 함수의 출력을 최대화하기 때문에 최적, 이 경우 최대값이 됩니다.
우리는 이것을 실제로 알지 못하지만 테스트 문제의 경우 베이지안 최적화 알고리즘이 그것을 찾을 수 있는지 확인하기 위해 함수의 실제 최상의 입력 및 출력을 아는 것이 좋습니다.
마지막으로, 먼저 노이즈가 있는 평가를 x축에 입력이 있고 y축에 점수가 있는 산점도로 표시한 다음 노이즈 없이 점수의 선 플롯으로 표시하는 플롯을 만들 수 있습니다.
최적화하려는 테스트 기능을 검토하는 전체 예는 다음과 같습니다.
예제를 실행하면 먼저 전역 최적값이 0.9인 입력값으로 보고되어 점수 0.81이 됩니다.
그런 다음 샘플(점)의 노이즈가 있는 평가와 목적 함수(선)의 노이즈가 없는 실제 모양을 보여주는 플롯이 생성됩니다.
참고: 결과는 알고리즘 또는 평가 절차의 확률적 특성 또는 수치 정밀도의 차이에 따라 달라질 수 있습니다. 예제를 몇 번 실행하고 평균 결과를 비교하는 것이 좋습니다.
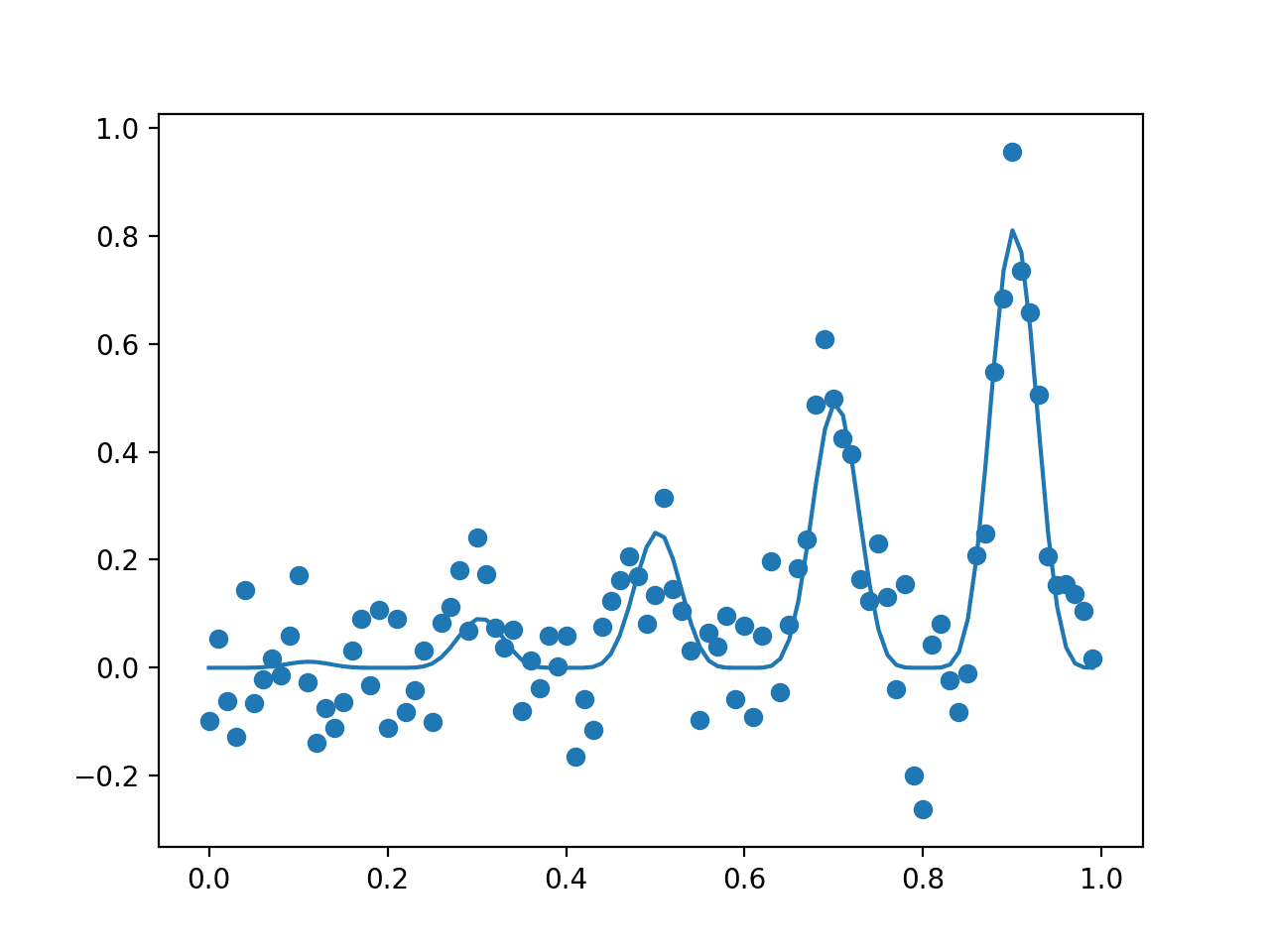
노이즈(점) 및 비노이즈(선) 목적 함수로 평가된 입력 샘플의 플롯
이제 테스트 문제가 있으므로 surrogate 함수를 훈련하는 방법을 검토해 보겠습니다.
대리 기능
대리 함수는 입력 예제와 출력 점수의 매핑을 가장 잘 근사화하는 데 사용되는 기술입니다.
확률론적으로, 사용 가능한 데이터 (D) 또는 P (f|D)가 주어지면 목적 함수 (f)의 조건부 확률을 요약합니다.
이를 위해 여러 기술을 사용할 수 있지만 가장 인기 있는 것은 모델을 모델에 대한 입력과 점수를 나타내는 데이터를 갖는 회귀 예측 모델링 문제로 문제를 처리하는 것입니다. 이것은 종종 랜덤 포리스트 또는 가우스 프로세스를 사용하여 가장 잘 모델링 됩니다.
가우스 프로세스 또는 GP는 다변량 가우스 분포를 가정하여 변수에 대한 공동 확률 분포를 구성하는 모델입니다. 따라서 많은 수의 함수를 효율적이고 효과적으로 요약할 수 있으며 모델에 더 많은 관찰을 사용할 수 있으므로 원활하게 전환할 수 있습니다.
이러한 부드러운 구조와 데이터를 기반으로 하는 새로운 함수로의 원활한 전환은 도메인을 샘플링할 때 바람직한 속성이며, 모델에 대한 다변량 가우스 기저량은 모델의 추정치가 표준 편차가 있는 분포의 평균이 된다는 것을 의미합니다. 나중에 획득 기능에 도움이 될 것입니다.
따라서 GP 회귀 모델을 사용하는 것이 선호되는 경우가 많습니다.
입력 샘플(X)에서 GaussianProcessRegressor scikit-learn 구현과 목적 함수(y)의 노이즈 평가를 사용하여 GP 회귀 모델을 맞출 수 있습니다.
먼저 모델을 정의해야 합니다. GP 모델을 정의할 때 중요한 측면은 커널입니다. 이것은 실제 데이터 관측값 사이의 거리 측정값을 기반으로 특정 지점에서 함수의 모양을 제어합니다. 다양한 커널 함수를 사용할 수 있으며 일부는 특정 데이터 세트에 대해 더 나은 성능을 제공할 수 있습니다.
기본적으로 잘 작동할 수 있는 방사형 기저 함수 또는 RBF가 사용됩니다.
일단 정의되면 fit()함수를 호출하여 훈련 데이터 세트에 직접 모델을 맞출 수 있습니다.
정의된 모델은 fit()에 대한 또 다른 호출에 의해 기존 데이터에 연결된 업데이트된 데이터를 사용하여 언제든지 다시 맞출 수 있습니다.
모델은 제공된 하나 이상의 샘플에 대한 비용을 추정합니다.
모델은 predict()함수를 호출하여 사용됩니다. 주어진 표본에 대한 결과는 해당 시점에서의 분포의 평균이 됩니다. 또한 인수를 지정하여 함수의 해당 지점에서 분포의 표준 편차를 얻을 수 있습니다 return_std=True; 예를 들어:
이 함수는 샘플링에 관심이 있는 지정된 지점에서 분포가 얇은 경우 경고를 발생시킬 수 있습니다.
따라서 예측을 할 때 모든 경고를 무음으로 설정할 수 있습니다. 아래의 surrogate()함수는 적합 모델과 하나 이상의 샘플을 사용하고 경고를 인쇄하지 않고 평균 및 표준 편차 예상 비용을 반환합니다.
언제든지 이 함수를 호출하여 하나 이상의 샘플의 비용을 추정할 수 있습니다(예: 다음 섹션에서 수집 함수를 최적화하려는 경우).
현재로서는 무작위 샘플에서 훈련된 후 도메인 전체에서 대리 함수가 어떻게 보이는지 보는 것이 흥미롭습니다.
먼저 GP 모델을 100 개의 데이터 포인트로 구성된 무작위 샘플과 실제 목적 함수 값에 노이즈으로 피팅하여이를 달성 할 수 있습니다. 그런 다음 이러한 점의 산점도를 그릴 수 있습니다. 다음으로, 입력 영역에서 그리드 기반 샘플을 수행하고 대리 함수를 사용하여 각 지점의 비용을 추정하고 결과를 선으로 플로팅할 수 있습니다.
우리는 대리 함수가 노이즈가 없는 실제 목적 함수의 대략적인 근사치를 가질 것으로 예상합니다.
아래의plot()함수는 실제 노이즈가 많은 목적 함수와 적합 모델의 랜덤 데이터 샘플이 주어지면 이 플롯을 생성합니다.
이를 함께 묶어 노이즈가 많은 샘플에 가우스 프로세스 회귀 모델을 피팅하고 샘플 대 대리 함수를 플로팅하는 전체 예제가 아래에 나열되어 있습니다.
예제를 실행하면 먼저 랜덤 표본을 추출하고 노이즈가 있는 목적 함수로 평가한 다음 GP 모델을 피팅합니다.
그런 다음 surrogate 함수를 통해 평가된 도메인 전체의 데이터 샘플과 점 그리드가 각각 점과 선으로 그려집니다.
참고: 결과는 알고리즘 또는 평가 절차의 확률적 특성 또는 수치 정밀도의 차이에 따라 달라질 수 있습니다. 예제를 몇 번 실행하고 평균 결과를 비교하는 것이 좋습니다.
이 경우 예상대로 플롯은 노이즈가 없는 기본 목적 함수의 조잡한 버전과 유사하며, 중요한 것은 실제 최대값이 있는 약 0.9의 피크를 갖는 것입니다.
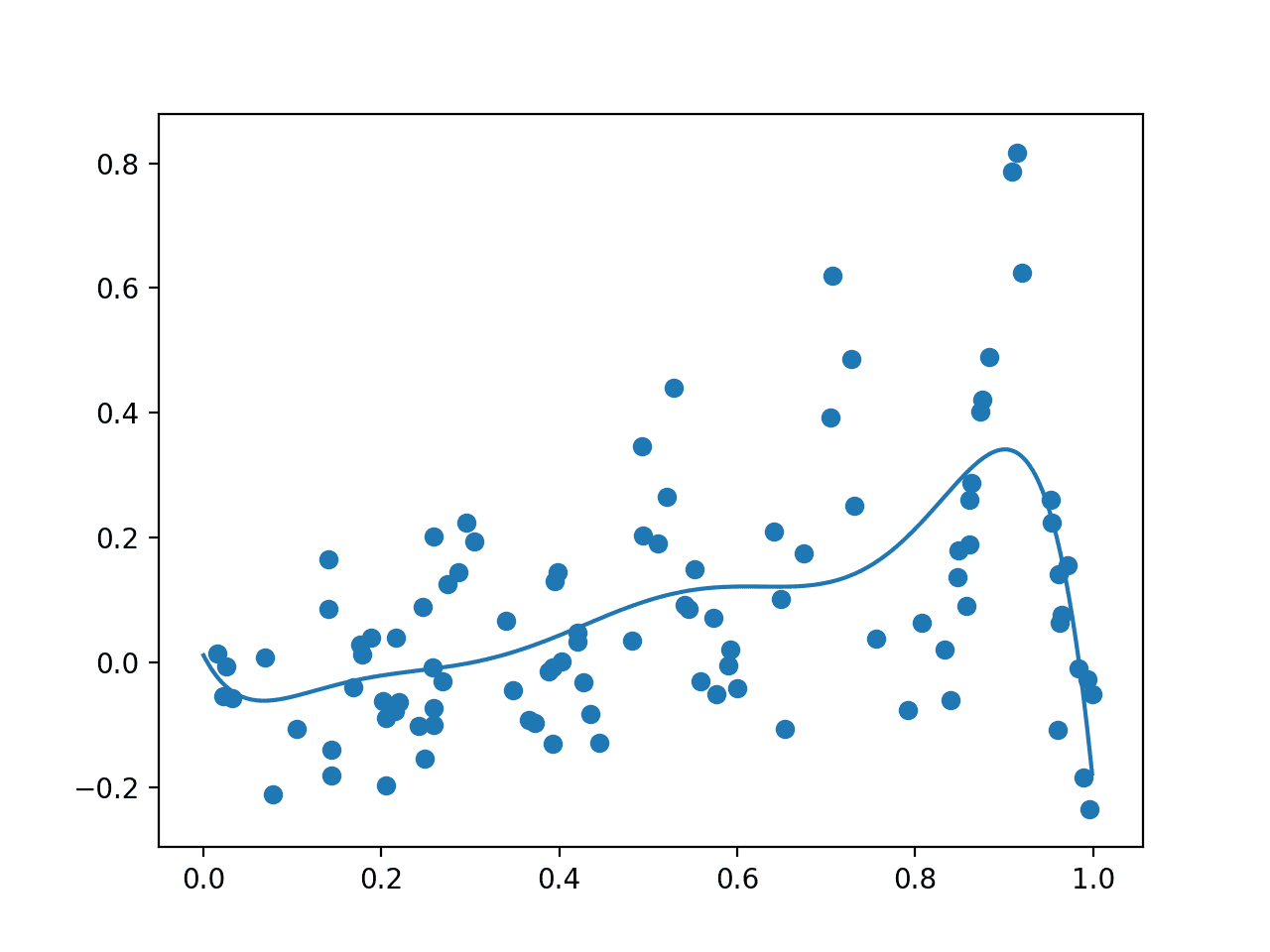
노이즈가 있는 평가(점)가 있는 랜덤 표본과 도메인(선)의 대리 함수를 보여주는 플롯입니다.
다음으로, 대리 함수를 샘플링하기 위한 전략을 정의해야 합니다.
획득 기능
대리 함수는 도메인에서 다양한 후보 샘플을 테스트하는 데 사용됩니다.
이러한 결과로부터, 하나 이상의 후보가 실제, 및 통상의 연습에서, 계산적으로 비용이 많이 드는 비용 함수로 선택되고 평가될 수 있습니다.
여기에는 대리 함수에 대한 응답으로 도메인을 탐색하는 데 사용되는 검색 전략과 대리 함수의 응답을 해석하고 점수를 매기는 데 사용되는 획득 함수의 두 부분이 포함됩니다.
무작위 샘플 또는 그리드 기반 샘플과 같은 간단한 검색 전략을 사용할 수 있지만 널리 사용되는 BFGS 알고리즘과 같은 로컬 검색 전략을 사용하는 것이 더 일반적입니다. 이 경우 예제를 간단하게 유지하기 위해 도메인의 무작위 검색 또는 무작위 샘플을 사용합니다.
여기에는 먼저 도메인에서 후보 샘플의 무작위 샘플을 추출하고 획득 함수로 평가한 다음 획득 기능을 최대화하거나 최고 점수를 제공하는 후보 샘플을 선택하는 작업이 포함됩니다. 아래의 opt_acquisition()함수는 이를 구현합니다.
획득 함수는 주어진 후보 표본(입력)이 실제 목적 함수로 평가할 가치가 있을 가능성을 채점하거나 추정하는 역할을 합니다.
대리 점수를 직접 사용할 수 있습니다. 또는 가우스 프로세스 모델을 대리 함수로 선택했다고 가정하면 획득 함수에서 이 모델의 확률 정보를 사용하여 주어진 샘플이 평가할 가치가 있는 확률을 계산할 수 있습니다.
사용할 수 있는 확률적 획득 함수에는 여러 가지 유형이 있으며, 각각은 착취적(탐욕스러운)과 탐색적이라는 점에서 서로 다른 절충안을 제공합니다.
세 가지 일반적인 예는 다음과 같습니다.
- 개선 가능성 (PI).
- 기대되는 개선 (EI).
- 신뢰 하한(LCB).
개선 가능성 방법이 가장 간단하지만 예상 개선 방법이 가장 일반적으로 사용됩니다.
이 경우 정규화 된 예상 개선의 정규 누적 확률로 계산되는 더 간단한 개선 확률 방법을 다음과 같이 계산합니다.
- PI = cdf((mu – best_mu) / stdev)
여기서 PI는 개선 확률이고, cdf()는 정규 누적 분포 함수이고, mu는 주어진 표본 x에 대한 대리 함수의 평균이고, stdev는 주어진 표본x에 대한 대리 함수의 표준 편차이고,best_mu는 지금까지 발견된 최상의 표본에 대한 대리 함수의 평균입니다.
0으로 나누기 오류를 피하기 위해 표준 편차에 매우 작은 숫자를 추가할 수 있습니다.
아래의 acquisition() 함수는 입력 샘플의 현재 훈련 데이터 세트, 새 후보 샘플의 배열 및 적합 GP 모델을 고려하여 이를 구현합니다.
완벽한 베이지안 최적화 알고리즘
이 모든 것을 베이지안 최적화 알고리즘에 연결할 수 있습니다.
주요 알고리즘에는 후보 샘플을 선택하고 목적 함수로 평가 한 다음 GP 모델을 업데이트하는 사이클이 포함됩니다.
전체 예제는 다음과 같습니다.
예제를 먼저 실행하면 검색 공간의 초기 무작위 샘플과 결과 평가가 생성됩니다. 그런 다음 GP 모델이 이 데이터에 적합합니다.
참고: 결과는 알고리즘 또는 평가 절차의 확률적 특성 또는 수치 정밀도의 차이에 따라 달라질 수 있습니다. 예제를 몇 번 실행하고 평균 결과를 비교하는 것이 좋습니다.
원시 관측치를 점으로 표시하고 전체 영역에서 대리 함수를 보여주는 플롯이 생성됩니다. 이 경우 초기 샘플은 도메인 전체에 걸쳐 양호한 분포를 가지며 대리 함수는 최적이 위치한 것으로 알고 있는 도메인 부분에 편향되어 있습니다.
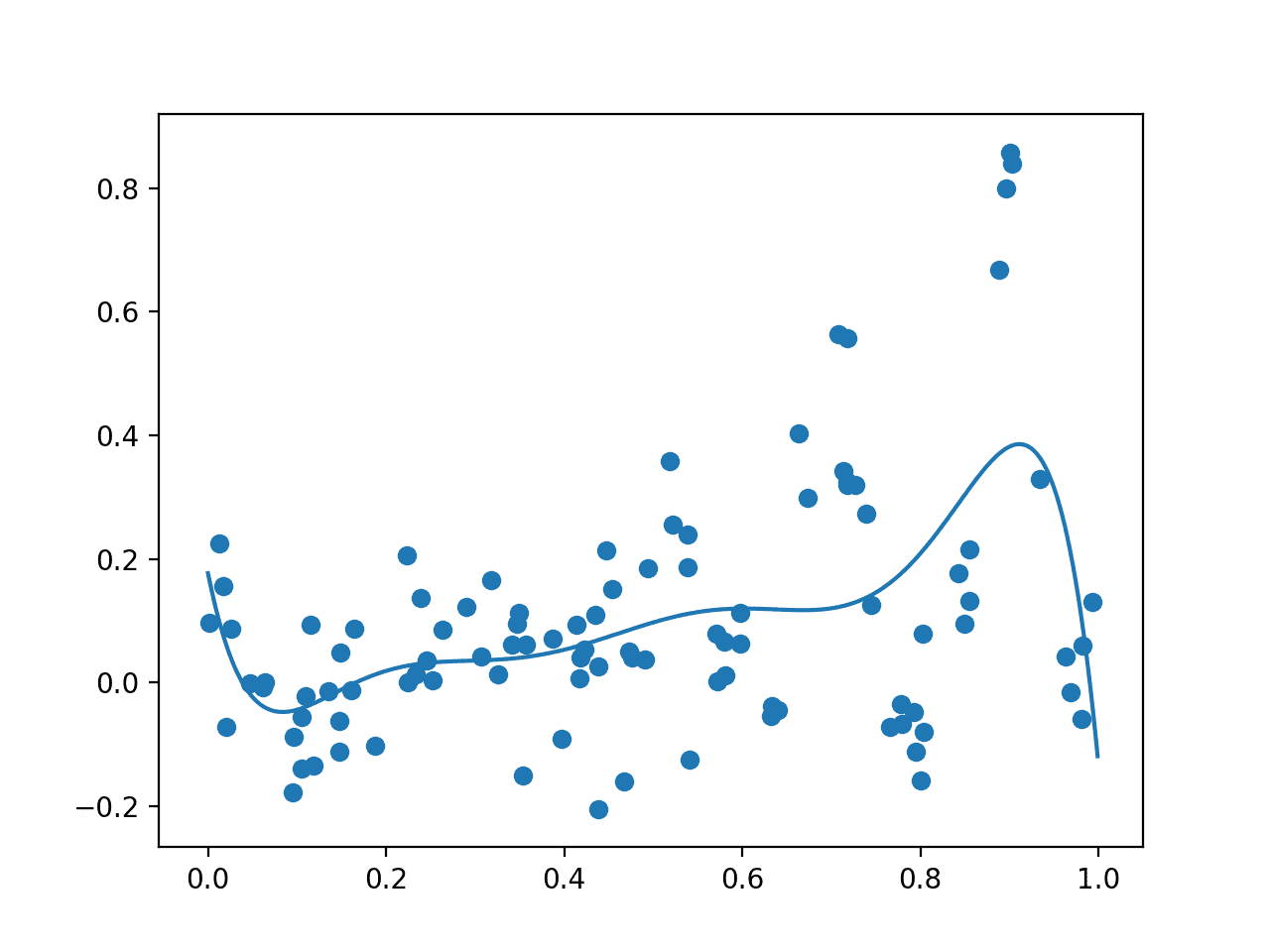
초기 표본(점)과 도메인(선)에 걸친 대리 함수의 플롯입니다.
그런 다음 알고리즘은 100주기 동안 반복하여 샘플을 선택하고 평가한 다음 데이터 세트에 추가하여 대리 함수를 업데이트하는 등의 작업을 반복합니다.
각 주기는 선택한 입력 값, 대리 함수의 추정 점수 및 실제 점수를 보고합니다. 이상적으로, 이러한 점수는 알고리즘이 검색 공간의 한 영역에 수렴함에 따라 점점 더 가까워질 것입니다.
다음으로 이전 플롯과 동일한 형식으로 최종 플롯이 생성됩니다.
이번에는 최적화 작업 중에 평가된 200개의 샘플이 모두 플로팅 됩니다. 우리는 알려진 최적 값 주변에서 샘플링이 너무 많을 것으로 예상할 수 있으며, 이것이 약 0.9의 5월 점으로 볼 수 있는 것입니다. 또한 대리 함수가 기본 대상 도메인을 더 강력하게 표현한다는 것을 알 수 있습니다.
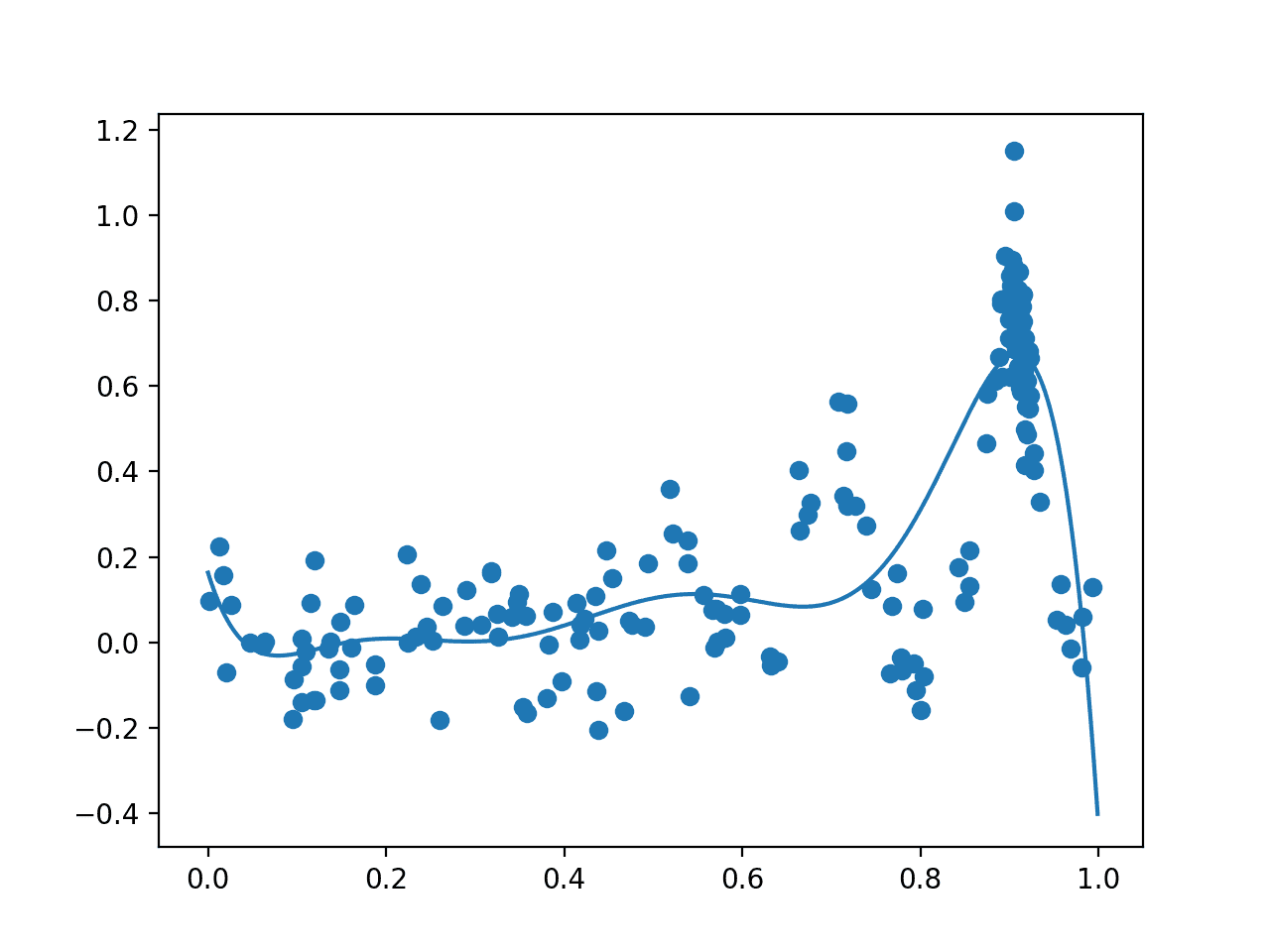
베이지안 최적화 후 도메인(선)에 걸친 모든 샘플(점)과 대리 함수의 플롯.
마지막으로, 최상의 입력값과 목적 함수 점수가 보고됩니다.
샘플링 노이즈가 없는 경우 최적값의 입력값은 0.9이고 출력값은 0.810입니다.
샘플링 노이즈가 주어지면 이 경우 최적화 알고리즘이 가까워져 입력값 0.905가 됩니다.
1 | Best Result: x=0.905, y=1.150 |
베이지안 최적화를 사용한 하이퍼 파라미터 튜닝
베이지안 최적화를 구현하여 작동 방식을 배우는 데 유용한 연습이 될 수 있습니다.
실제로 프로젝트에서 베이지안 최적화를 사용할 때는 오픈 소스 라이브러리에서 제공하는 표준 구현을 사용하는 것이 좋습니다. 이는 버그를 방지하고 광범위한 구성 옵션과 속도 향상을 활용하기 위한 것입니다.
베이지안 최적화를 위한 두 가지 인기 있는 라이브러리에는 Scikit-Optimize와 HyperOpt가 있습니다. 머신러닝에서 이러한 라이브러리는 알고리즘의 하이퍼 매개 변수를 조정하는 데 자주 사용됩니다.
하이퍼파라미터 튜닝은 평가 함수가 계산 비용이 많이 들고(예: 각 하이퍼파라미터 세트에 대한 모델 훈련) 노이즈가 많고(예: 훈련 데이터 및 확률적 학습 알고리즘의 노이즈) 베이지안 최적화에 적합합니다.
이 섹션에서는 Scikit-Optimize 라이브러리를 사용하여 간단한 테스트 분류 문제에 대해 k-최근접 이웃 분류자의 하이퍼파라미터를 최적화하는 방법을 간략하게 살펴보겠습니다. 이렇게 하면 자신의 프로젝트에서 사용할 수 있는 유용한 템플릿이 제공됩니다.
Scikit-Optimize 프로젝트는SciPy 및 NumPy를 사용하는 애플리케이션 또는 scikit-learn 머신러닝 알고리즘을 사용하는 애플리케이션에 베이지안 최적화에 대한 액세스를 제공하도록 설계되었습니다.
먼저 pip를 사용하여 쉽게 얻을 수 있는 라이브러리를 설치해야 합니다. 예를 들어:
또한 이 예제에 대해 scikit-learn이 설치되어 있다고 가정합니다.
일단 설치되면 scikit-optimize 를 사용하여 scikit-learn 알고리즘의 하이퍼파라미터를 최적화할 수 있는 두 가지 방법이 있습니다. 첫 번째는 검색 공간에서 직접 최적화를 수행하는 것이고, 두 번째는 무작위 및 그리드 검색을 위해 scikit-learn 네이티브 클래스의 형제 인 BayesSearchCV 클래스를 사용하는 것입니다.
이 예제에서는 하이퍼파라미터를 직접 최적화하는 더 간단한 접근 방식을 사용합니다.
첫 번째 단계는 데이터를 준비하고 모델을 정의하는 것입니다. 각각 2개의 기능과 3개의 클래스 레이블이 있는 500개의 예제가 있는 make_blobs() 함수를통해 간단한 테스트 분류 문제를 사용합니다. 그런 다음 KNeighborsClassifier 알고리즘을 사용합니다.
다음으로 검색 공간을 정의해야 합니다.
이 경우 이웃 수(n_neighbors)와 이웃 함수의 모양(p)을 조정합니다. 이렇게 하려면 지정된 데이터 형식에 대해 범위를 정의해야 합니다. 이 경우 정수이며, 최소값, 최대값 및 scikit-learn 모델에 대한 파라미터 이름으로 정의됩니다. 알고리즘의 경우 Real() 및 범주형() 데이터형을 쉽게 최적화할 수 있습니다.
다음으로, 주어진 하이퍼파라미터 세트를 평가하는 데 사용할 함수를 정의해야 합니다. 이 함수를 최소화하려고 하므로 반환되는 값이 작을수록 더 나은 성능의 모델을 나타내야 합니다.
scikit-optimize 프로젝트의 use_named_args() 데코레이터를 함수 정의에 사용하여 검색 공간에서 특정 매개 변수 집합으로 함수를 직접 호출 할 수 있습니다.
따라서 사용자 지정 함수는 하이퍼파라미터 값을 인수로 사용하며, 이를 구성하기 위해 모델에 직접 제공할 수 있습니다. 함수에 대한 **params인수를 사용하여 파이썬에서 일반적으로 이러한 인수를 정의한 다음 set_params(**) 함수를 통해 모델에 전달할 수 있습니다.
이제 모델이 구성되었으므로 평가할 수 있습니다. 이 경우 데이터 세트에 대해 5겹 교차 검증을 사용하고 각 접기의 정확도를 평가합니다. 그런 다음 모델의 성능을 1에서 이러한 접기의 평균 정확도를 뺀 값으로 보고할 수 있습니다. 즉, 정확도가 1.0인 완벽한 모델은 0.0(1.0 – 평균 정확도) 값을 반환합니다.
이 함수는 데이터 세트를 로드하고 모델을 정의한 후에 정의되어 데이터 세트와 모델이 모두 범위 내에 있고 직접 사용할 수 있습니다.
다음으로 최적화를 수행할 수 있습니다.
이는 목적 함수의 이름과 정의된 검색 공간으로 gp_minimize() 함수를호출하여 수행됩니다.
기본적으로 이 함수는 최상의 전략을 파악하려고 시도하는 ‘gp_hedge‘ 획득 함수를 사용하지만 acq_func인수를 통해 구성할 수 있습니다. 최적화는 기본적으로 100회 반복에 대해서도 실행되지만 n_calls인수를 통해 제어할 수 있습니다.
일단 실행되면 “fun” 속성을 통해 최고 점수에 액세스할 수 있고 “x” 배열 속성을 통해 최상의 하이퍼파라미터 집합에 액세스할 수 있습니다.
이 모든 것을 함께 묶어 전체 예제가 아래에 나열되어 있습니다.
예제를 실행하면 베이지안 최적화를 사용하여 하이퍼파라미터 튜닝이 실행됩니다.
코드는 다음과 같은 많은 경고 메시지를 보고할 수 있습니다.
이는 예상된 동작이며 동일한 하이퍼파라미터 구성이 두 번 이상 평가되기 때문에 발생합니다.
참고: 결과는 알고리즘 또는 평가 절차의 확률적 특성 또는 수치 정밀도의 차이에 따라 달라질 수 있습니다. 예제를 몇 번 실행하고 평균 결과를 비교하는 것이 좋습니다.
이 경우 모델은 3개의 이웃과 2의 p-값을 가진 평균 5배 교차 검증을 통해 약 97%의 정확도를 달성했습니다.
1 2 | Best Accuracy: 0.976 Best Parameters: n_neighbors=3, p=2 |
추가 정보
이 섹션에서는 더 자세히 알아보려는 경우 주제에 대한 더 많은 리소스를 제공합니다.
논문
- 고가의 비용 함수의 베이지안 최적화에 대한 자습서, 활성 사용자 모델링 및 계층적 강화 학습에 적용, 2010.
- 머신러닝 알고리즘의 실용적인 베이지안 최적화, 2012.
- 베이지안 최적화에 대한 자습서, 2018.
API
기사
요약
이 자습서에서는 복잡한 최적화 문제의 직접 검색을 위한 베이지안 최적화를 발견했습니다.
특히 다음 내용을 배웠습니다.
- 글로벌 최적화는 블랙 박스와 종종 볼록하지 않고, 비선형이며, 노이즈가 많고, 계산 비용이 많이 드는 목적 함수를 포함하는 어려운 문제입니다.
- 베이지안 최적화는 전역 최적화를 위한 확률적으로 원칙적인 방법을 제공합니다.
- 베이지안 최적화를 처음부터 구현하는 방법과 오픈 소스 구현을 사용하는 방법.