





정보 엔트로피에 대한 간략한 소개
정보 이론은 시끄러운(noisy) 채널을 통해 데이터를 전송하는 것과 관련된 수학의 하위 분야입니다.
정보 이론의 초석은 메시지에 얼마나 많은 정보가 있는지 정량화하는 아이디어입니다. 보다 일반적으로 이것은 이벤트의 정보와 엔트로피라고하는 확률 변수를 정량화하는 데 사용할 수 있으며 확률을 사용하여 계산됩니다.
정보 및 엔트로피 계산은 머신러닝에서 유용한 도구이며 기능 선택, 의사 결정 트리 작성 및 보다 일반적으로 분류 모델 피팅과 같은 기술의 기초로 사용됩니다. 따라서 머신러닝 실무자는 정보와 엔트로피에 대한 강력한 이해와 직관이 필요합니다.
이 게시물에서는 정보 엔트로피에 대한 간략한 소개를 할 것입니다.
이 게시물을 읽은 후 다음을 알게 될 것입니다.
- 정보 이론은 데이터 압축 및 전송과 관련이 있으며 확률을 기반으로 하여 머신러닝을 지원합니다.
- 정보는 비트 단위로 측정된 이벤트에 대한 놀라움의 양을 정량화하는 방법을 제공합니다.
- 엔트로피는 확률 변수에 대한 확률 분포에서 추출한 사건을 나타내는 데 필요한 평균 정보량의 측정값을 제공합니다.
개요
이 자습서는 세 부분으로 나뉩니다. 그들은:
- 정보 이론이란 무엇입니까?
- 이벤트에 대한 정보 계산
- 랜덤 변수에 대한 엔트로피 계산
정보 이론이란 무엇입니까?
정보 이론은 의사 소통을 위한 정보를 정량화하는 것과 관련된 연구 분야입니다.
수학의 하위 분야이며 데이터 압축 및 신호 처리의 한계와 같은 주제와 관련이 있습니다. 이 분야는 Claude Shannon이 미국 전화 회사 Bell Labs에서 근무하는 동안 제안하고 개발했습니다.
정보 이론은 데이터를 간결한 방식으로 표현하는 것(데이터 압축 또는 소스 코딩으로 알려진 작업)과 오류에 강한 방식으로 데이터를 전송 및 저장하는 것(오류 수정 또는 채널 코딩으로 알려진 작업)과 관련이 있습니다.
— 페이지 56, 머신러닝: 확률론적 관점, 2012.
정보의 기본 개념은 사건, 확률 변수 및 분포와 같은 정보의 양을 정량화하는 것입니다.
정보의 양을 정량화 하려면 확률을 사용해야 하므로 정보 이론과 확률의 관계가 필요합니다.
정보 측정은 의사 결정 트리 구성 및 분류자 모델 최적화와 같은 인공 지능 및 머신러닝에서 널리 사용됩니다.
따라서 정보 이론과 머신러닝 사이에는 중요한 관계가 있으며 실무자는 해당 분야의 기본 개념 중 일부에 익숙해야 합니다.
정보 이론과 머신러닝을 통합하는 이유는 무엇입니까? 그들은 같은 동전의 양면이기 때문입니다. […] 정보 이론과 머신러닝은 여전히 함께 속합니다. 두뇌는 궁극적인 압축 및 통신 시스템입니다. 또한 데이터 압축 및 오류 수정 코드를 위한 최첨단 알고리즘은 머신러닝과 동일한 도구를 사용합니다.
— 페이지 v, 정보 이론, 추론 및 학습 알고리즘, 2003.
이벤트에 대한 정보 계산
정보를 정량화 하는 것은 정보 이론 분야의 기초입니다.
정보를 정량화 하는 직관은 이벤트에 얼마나 많은 놀라움이 있는지 측정하는 아이디어입니다. 드문 사건 (낮은 확률)은 더 놀랍고 따라서 일반적인 사건 (높은 확률)보다 더 많은 정보를 가지고 있습니다.
- 낮은 확률의 사건 : 높은 정보 (놀라움).
- 높은 확률의 사건: 낮은 정보(놀라운 일이 아님).
정보 이론의 기본 직관은 가능성이 낮은 사건이 발생했다는 것을 배우는 것이 가능성이 있는 사건이 발생했다는 것을 배우는 것보다 더 유익하다는 것입니다.
— 페이지 73,딥 러닝, 2016.
희귀 사건은 더 불확실하거나 더 놀랍고 일반적인 사건보다 더 많은 정보가 필요합니다.
사건의 확률을 사용하여 사건에 존재하는 정보의 양을 계산할 수 있습니다. 이를 “섀넌 정보”, “자체 정보” 또는 간단히 “정보“라고 하며 다음과 같이 이산 이벤트 x에 대해 계산할 수 있습니다.
- 정보 (x) = -로그 ( p (x) )
여기서 log()는 밑이 2인 로그이고 p(x)는 이벤트x의 확률입니다.
밑수 2 로그의 선택은 정보 측정값의 단위가 비트(이진수)임을 의미합니다. 이는 정보 처리 의미에서 이벤트를 나타내는 데 필요한 비트 수로 직접 해석될 수 있습니다.
정보 계산은 종종h ()로 작성됩니다. 예를 들어:
- h(x) = -log( p(x) )
음수 부호는 결과가 항상 양수 또는 0임을 보장합니다.
사건의 확률이 1.0 또는 확실성(예: 놀라움이 없음)일 때 정보는 0이 됩니다.
몇 가지 예를 들어 구체적으로 설명해 보겠습니다.
하나의 공정한 동전을 던지는 것을 고려하십시오. 머리 (및 꼬리)의 확률은 0.5입니다. log2()함수를 사용하여 Python에서 머리를 뒤집기 위한 정보를 계산할 수 있습니다.
예제를 실행하면 이벤트의 확률이 50%로 출력되고 이벤트에 대한 정보 콘텐츠가 1비트로 출력됩니다.
동일한 동전이 n 번 뒤집힌 경우이 던지기 순서에 대한 정보는 n 비트가됩니다.
동전이 공정하지 않고 앞면의 확률이 10 % (0.1)라면 이벤트는 더 드물고 3 비트 이상의 정보가 필요합니다.
우리는 또한 공정한 6면 주사위의 단일 롤에서 정보를 탐색 할 수 있습니다 (예 : 6 롤링의 정보).
우리는 숫자를 굴릴 확률이 1/6이라는 것을 알고 있으며, 이는 동전 던지기의 1/2보다 작은 숫자이므로 더 많은 놀라움이나 더 많은 양의 정보를 기대할 수 있습니다.
예제를 실행하면 직관이 정확하고 실제로 공정한 주사위의 단일 롤에 2.5 비트 이상의 정보가 있음을 알 수 있습니다.
밑수-2 대신 다른 로그를 사용할 수 있습니다. 예를 들어, 정보를 계산할 때 밑수-e(오일러 수)를 사용하는 자연 로그를 사용하는 것도 일반적이며, 이 경우 단위를 “nats“라고 합니다.
우리는 확률이 낮은 사건이 더 많은 정보를 가지고 있다는 직관을 더욱 발전시킬 수 있습니다.
이를 명확히 하기 위해 0과 1 사이의 확률에 대한 정보를 계산하고 각각에 해당하는 정보를 플로팅할 수 있습니다. 그런 다음 확률 대 정보의 플롯을 만들 수 있습니다. 플롯이 높은 정보를 가진 낮은 확률로부터 낮은 정보를 가진 높은 확률로 하향 곡선을 그릴 것으로 예상합니다.
전체 예제는 다음과 같습니다.
예제를 실행하면 확률 대 정보의 플롯이 비트 단위로 생성됩니다.
우리는 낮은 확률의 사건이 더 놀랍고 더 많은 정보를 전달하고 높은 확률의 사건의 보완이 더 적은 정보를 전달하는 예상 관계를 볼 수 있습니다.
우리는 또한 이 관계가 선형이 아니라 실제로 약간 하위 선형임을 알 수 있습니다. 이것은 log 함수의 사용을 고려할 때 의미가 있습니다.
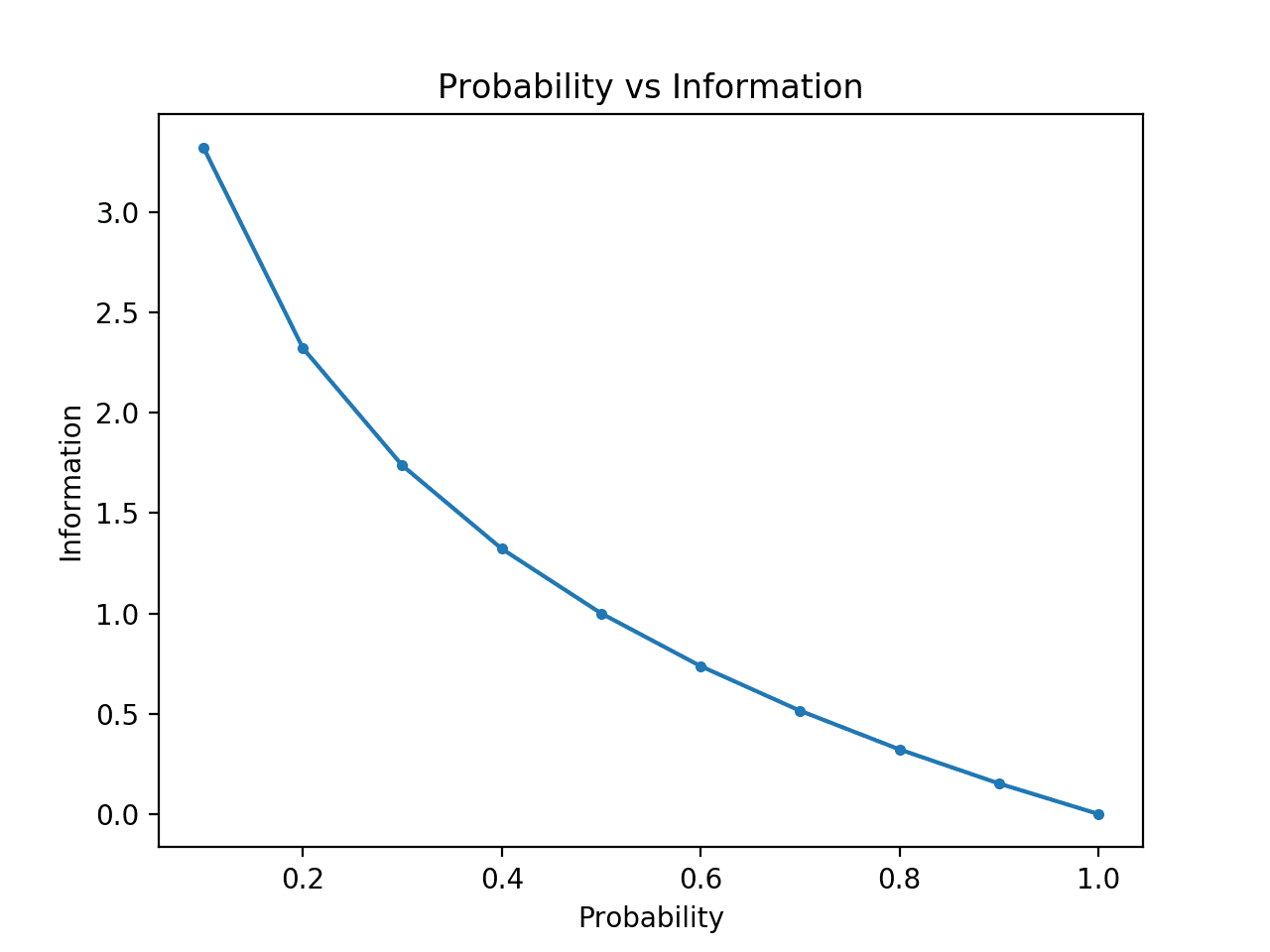
확률 대 정보의 플롯
랜덤 변수에 대한 엔트로피 계산
또한 확률 변수에 얼마나 많은 정보가 있는지 정량화할 수 있습니다.
예를 들어, 확률 분포가 p인 랜덤 변수 X에 대한 정보를 계산하려는 경우 함수 H()로 작성할 수 있습니다. 예를 들어:
- H(X)
실제로 랜덤 변수에 대한 정보를 계산하는 것은 랜덤 변수에 대한 사건의 확률 분포에 대한 정보를 계산하는 것과 같습니다.
랜덤 변수에 대한 정보를 계산하는 것을 “정보 엔트로피”, “섀넌 엔트로피” 또는 간단히 “엔트로피“라고 합니다. 그것은 둘 다 불확실성과 관련이 있다는 점에서 유추에 의한 물리학의 엔트로피 아이디어와 관련이 있습니다.
엔트로피에 대한 직관은 확률 변수에 대한 확률 분포에서 도출된 이벤트를 나타내거나 전송하는 데 필요한 평균 비트 수입니다.
… 분포의 섀넌 엔트로피는 해당 분포에서 가져온 이벤트의 예상 정보 양입니다. 그것은 분포 P에서 가져온 기호를 인코딩하는 데 평균적으로 필요한 비트 수에 대한 하한을 제공합니다.
— 페이지 74,딥 러닝, 2016.
엔트로피는 다음과 같이 K이산 상태의 k를 갖는 랜덤 변수 X에 대해 계산할 수 있습니다.
- H (X) = -sum (K p (k)의 각 k * log (p (k)))
그것은 각 사건의 확률의 합에 각 사건의 확률 로그를 곱한 음수입니다.
정보와 마찬가지로 log()함수는 base-2를 사용하고 단위는 비트입니다. 대신 자연 로그를 사용할 수 있으며 단위는 nats가됩니다.
가장 낮은 엔트로피는 확률이 1.0인 단일 이벤트가 있는 확률 변수에 대해 계산됩니다. 랜덤 변수에 대한 가장 큰 엔트로피는 모든 사건이 동일하게 발생할 가능성이 있는 경우입니다.
공정한 주사위 굴림을 고려하고 변수의 엔트로피를 계산할 수 있습니다. 각 결과는 1/6의 동일한 확률을 가지므로 균일한 확률 분포입니다. 따라서 평균 정보는 이전 섹션에서 계산된 단일 이벤트에 대해 동일한 정보일 것으로 예상합니다.
예제를 실행하면 엔트로피가 2.5비트 이상으로 계산되며, 이는 단일 결과에 대한 정보와 동일합니다. 모든 결과가 동등하게 가능성이 높기 때문에 평균 정보가 정보의 하한과 동일하기 때문에 이는 의미가 있습니다.
각 사건의 확률을 알고 있다면 entropy() SciPy 함수를사용하여 엔트로피를 직접 계산할 수 있습니다.
예를 들어:
예제를 실행하면 수동으로 계산한 것과 동일한 결과가 보고됩니다.
확률 분포의 엔트로피에 대한 직관을 더욱 발전시킬 수 있습니다.
엔트로피는 분포에서도 무작위로 그려진 것을 나타내는 데 필요한 비트 수입니다 (예 : 평균 이벤트). 동전 던지기와 같은 두 개의 이벤트가 있는 간단한 분포에 대해 이것을 탐색할 수 있지만 이 두 이벤트에 대해 서로 다른 확률을 탐색하고 각각에 대한 엔트로피를 계산할 수 있습니다.
편향된 확률 분포와 같이 하나의 이벤트가 지배하는 경우 놀라움이 적고 분포의 엔트로피가 낮아집니다. 같거나 거의 동일한 확률 분포와 같이 다른 이벤트를 지배하지 않는 경우 더 크거나 최대 엔트로피를 예상합니다.
- 비뚤어진 확률 분포(놀랍지 않음): 낮은 엔트로피.
- 균형 확률 분포 (놀라운) : 높은 엔트로피.
분포에서 사건의 편향된 확률에서 동일한 확률로 전환하면 엔트로피가 낮게 시작하여 증가할 것으로 예상되며, 특히 불가능/확실성(각각 0과 1의 확률)이 있는 사건의 경우 가장 낮은 엔트로피 0.0에서 동일한 확률을 가진 사건의 경우 가장 큰 엔트로피 1.0으로 증가합니다.
아래 예제에서는 이를 구현하여 이 전환에서 각 확률 분포를 만들고 각각에 대한 엔트로피를 계산하고 결과를 플로팅합니다.
예제를 실행하면 [0,1]개의 확률부터 [0.5,0.5]개의 확률까지 6개의 확률 분포가 생성됩니다.
예상대로 이벤트 분포가 편향에서 균형으로 변경됨에 따라 엔트로피가 최소값에서 최대값으로 증가하는 것을 볼 수 있습니다.
즉, 확률 분포에서 도출된 평균 사건이 놀랍지 않다면 더 낮은 엔트로피를 얻는 반면, 놀라운 경우 더 큰 엔트로피를 얻습니다.
우리는 전환이 선형이 아니라 초선형임을 알 수 있습니다. 또한 두 이벤트에 대해 [0.6, 0.4]로 계속 전환하고 [1.0, 0.0]으로 계속 전환하여 역포물선 모양을 형성하면 이 곡선이 대칭임을 알 수 있습니다.
0 값의 로그를 계산하지 않기 위해 엔트로피를 계산할 때 확률에 작은 값을 추가해야 했으며, 이로 인해 숫자가 아닌 무한대가 됩니다.
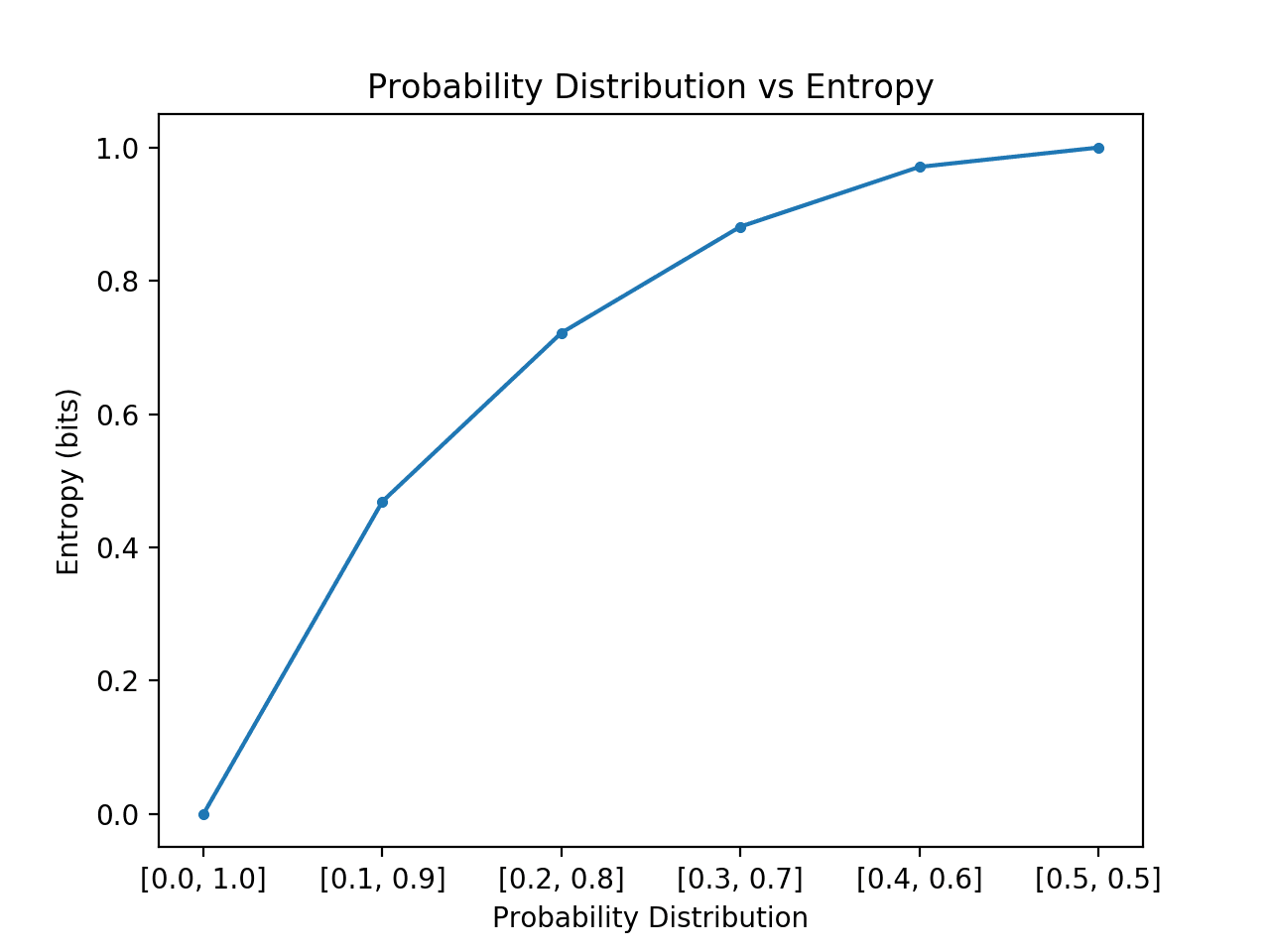
확률 분포 대 엔트로피 플롯
랜덤 변수에 대한 엔트로피를 계산하면 상호 정보 (정보 획득)와 같은 다른 측정의 기초가 제공됩니다.
엔트로피는 또한 교차 엔트로피와 KL 발산을 갖는 두 확률 분포 간의 차이를 계산하기 위한 기초를 제공합니다.
추가 정보
이 섹션에서는 더 자세히 알아보려는 경우 주제에 대한 더 많은 리소스를 제공합니다.
책
- 정보 이론, 추론 및 학습 알고리즘, 2003.