





주어진 확률 변수에 대한 확률 분포 간의 차이를 정량화 하는 것이 종종 바람직합니다. 이것은 실제 확률 분포와 관찰 된 확률 분포의 차이를 계산하는 데 관심이 있을 수 있는 머신러닝에서 자주 발생합니다. 이것은 Kullback-Leibler Divergence (KL 발산) 또는 상대 엔트로피와 같은 정보 이론의 기술과 KL 발산의 정규화 되고 대칭적인 버전을 제공하는 Jensen-Shannon Divergence를 사용하여 달성 할 […]
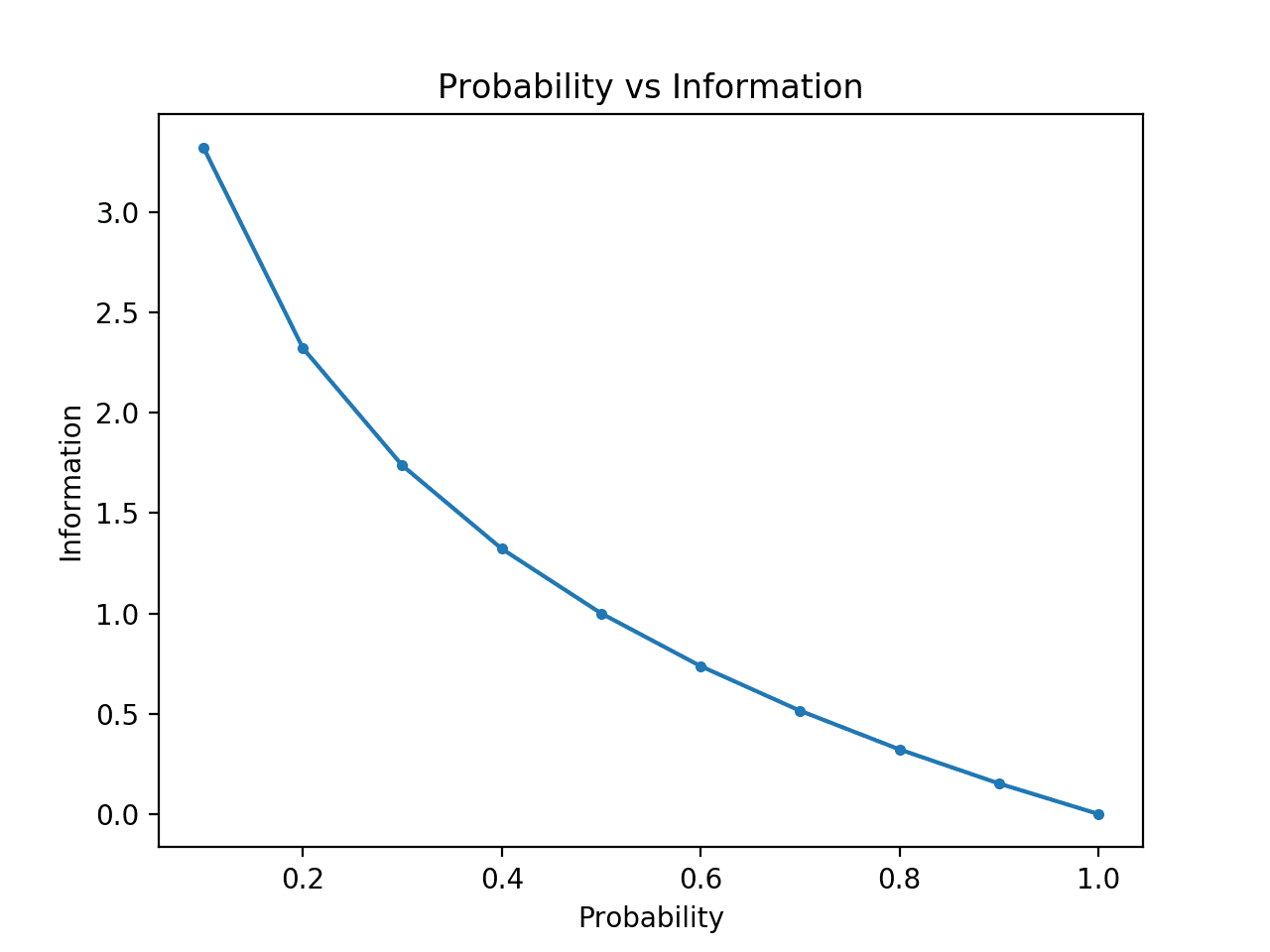
정보 이론은 시끄러운(noisy) 채널을 통해 데이터를 전송하는 것과 관련된 수학의 하위 분야입니다. 정보 이론의 초석은 메시지에 얼마나 많은 정보가 있는지 정량화하는 아이디어입니다. 보다 일반적으로 이것은 이벤트의 정보와 엔트로피라고하는 확률 변수를 정량화하는 데 사용할 수 있으며 확률을 사용하여 계산됩니다. 정보 및 엔트로피 계산은 머신러닝에서 유용한 도구이며 기능 선택, 의사 결정 트리 작성 및 보다 일반적으로 분류 […]
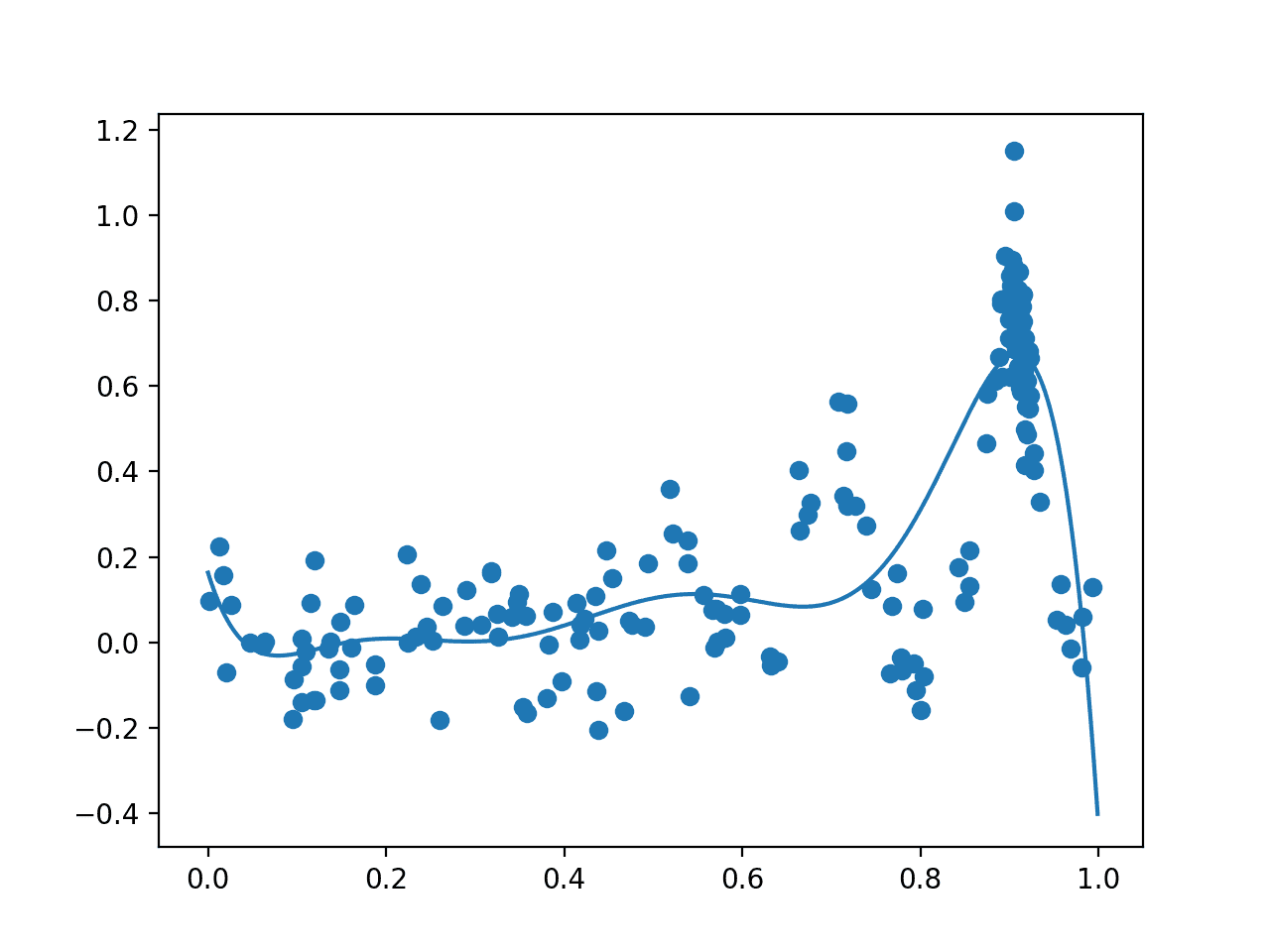
이 자습서에서는 복잡한 최적화 문제에 대해 베이지안 최적화 알고리즘을 구현하는 방법을 알아봅니다. 전역 최적화는 주어진 목적 함수의 최소 또는 최대 비용을 초래하는 입력값을 찾는 어려운 문제입니다. 일반적으로 목적 함수의 형식은 분석하기가 복잡하고 다루기 어려우며 종종 볼록하지 않고, 비선형이며, 고차원이고, 노이즈가 많고, 계산 비용이 많이 듭니다. 베이지안 최적화는 효율적이고 효과적인 전역 최적화 문제를 검색하도록 지시하는 Bayes 정리를 기반으로 […]
분류는 주어진 입력 데이터 샘플에 레이블을 할당하는 것과 관련된 예측 모델링 문제입니다. 분류 예측 모델링의 문제는 데이터 샘플이 주어진 클래스 레이블의 조건부 확률을 계산하는 것으로 구성될 수 있습니다. Bayes 정리는 이 조건부 확률을 계산하는 원칙적인 방법을 제공하지만 실제로는 엄청난 수의 샘플(매우 큰 크기의 데이터 세트)이 필요하고 계산 비용이 많이 듭니다. 대신, Bayes 정리의 계산은 각 입력 […]
Bayes 정리는 조건부 확률을 계산하는 원칙적인 방법을 제공합니다. 직관이 종종 실패하는 사건의 조건부 확률을 쉽게 계산하는 데 사용할 수 있지만 믿을 수 없을 정도로 간단한 계산입니다. 확률 분야에서 강력한 도구이지만 Bayes 정리는 머신러닝 분야에서도 널리 사용됩니다. 모델을 훈련 데이터 세트에 맞추기 위한 확률 프레임워크(줄여서 최대 사후 또는 MAP라고 함)에서의 사용과 Bayes 최적 분류기 및 Naive […]
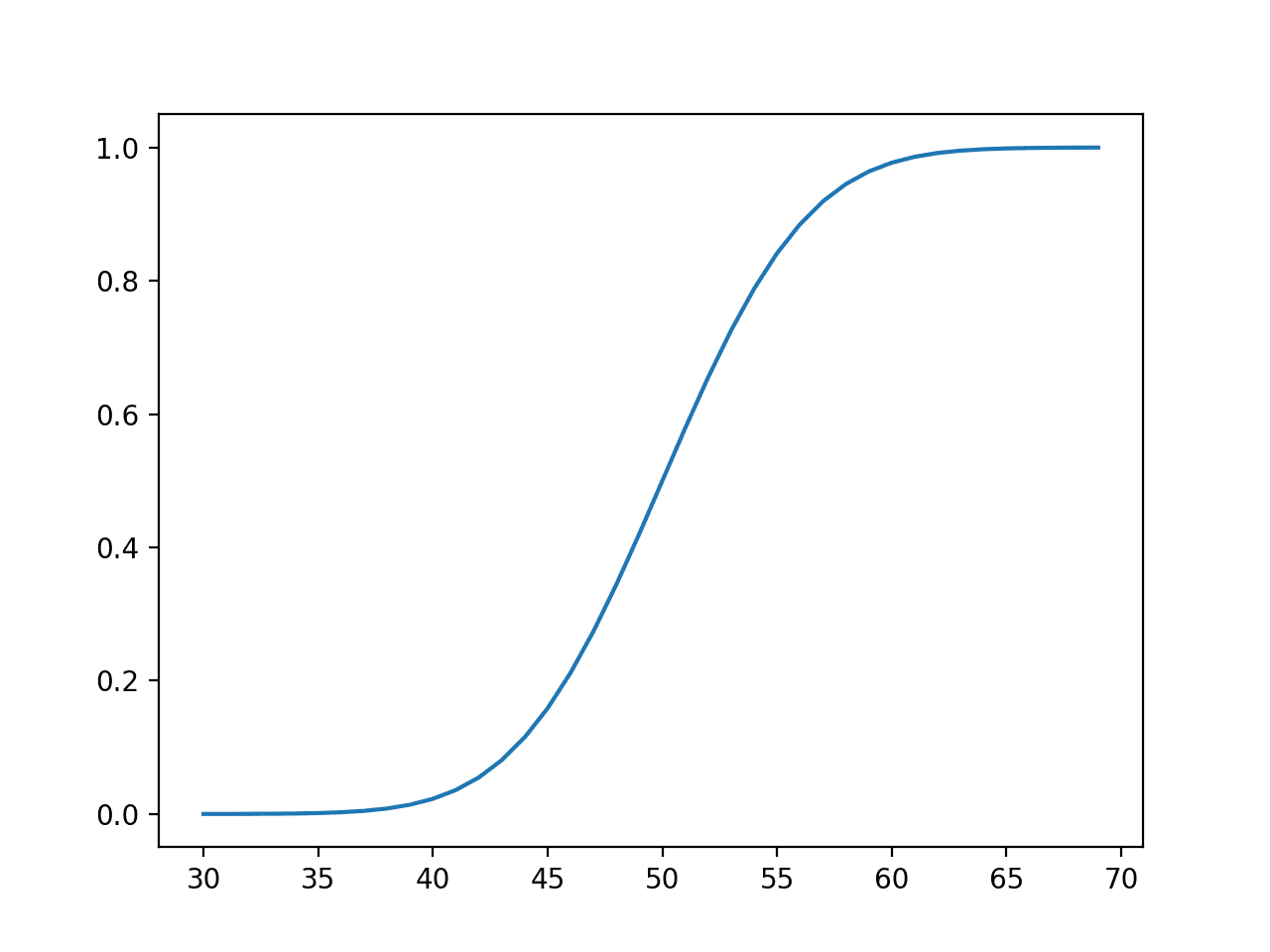
연속 확률 변수에 대한 확률은 연속 확률 분포로 요약할 수 있습니다. 연속 확률 분포는 머신러닝, 특히 모델에 대한 수치 입력 및 출력 변수의 분포와 모델에 의한 오류 분포에서 발생합니다. 정규 연속 확률 분포에 대한 지식은 또한 많은 머신러닝 모델에 의해 수행되는 밀도 및 매개 변수 추정에서보다 일반적으로 요구됩니다. 따라서 연속 확률 분포는 응용 머신러닝에서 중요한 […]
이산 확률 변수에 대한 확률은 이산확률 분포로 요약할 수 있습니다. 이산 확률 분포는 머신러닝, 특히 이진 및 다중 클래스 분류 문제의 모델링 뿐만 아니라 신뢰 구간 계산과 같은 이진 분류 모델의 성능 평가 및 자연어 처리를 위한 텍스트의 단어 분포 모델링에도 사용됩니다. 이산 확률 분포에 대한 지식은 분류 작업을 위한 딥러닝 신경망의 출력 계층에서 활성화 함수를 선택하고 […]
확률 계산은 직관적이지 않습니다. 우리의 두뇌는 문제를 생각하고 확률을 올바르게 계산하는 대신 지름길을 택하고 잘못된 답을 얻는 데 너무 열심입니다. 응용 확률의 고전적인 문제를 해결하는 것이 문제를 명확하게 하고 직관을 개발하는 데 유용할 수 있습니다. 생일 문제, 남자 또는 여자 문제, 몬티 홀 문제와 같은 이러한 문제는 올바른 해결책에 도달하기 위해 주변 확률, 조건부 확률 […]
단일 확률 변수에 대한 확률은 간단하지만 두 개 이상의 변수를 고려할 때 복잡해질 수 있습니다. 우리는 다음과 같은 확률에 대해 관심을 갖게 될 수 있습니다. 결합 확률 : 두 개의 동시 사건에 대한 확률 조건부 확률 : 다른 사건의 발생을 감안할 때 한 사건의 확률 주변 확률 : 다른 변수에 관계없이 일어나는 사건의 확률 이러한 […]
확률은 확률 변수 결과의 불확실성을 정량화합니다. 단일 변수에 대한 확률을 이해하고 계산하는 것은 비교적 쉽습니다. 그럼에도 불구하고 머신러닝에는 종종 복잡하고 알려지지 않은 방식으로 상호 작용하는 많은 확률 변수가 있습니다. 여러 확률 변수에 대한 확률을 정량화하는 데 사용할 수 있는 특정 기술(예: 결합 확률, 한계 확률 및 조건부 확률)이 있습니다. 이러한 기술은 예측 모델을 데이터에 적용하는 […]